With Hypothesis 1, a further paradox arises: If the structure of our human body (including its brain) is designed such that there is no direct, permanent one-to-one mapping of the real physical world outside the brain into the internal states of the body (including the brain), how can humans then make and use ’empirically true statements’ about something outside the body or outside the brain?
In everyday life, we can all have the following experiences:
When at least two people are involved and they have no special limitations, we can distinguish the following cases:
There is an object with certain properties that the involved persons can perceive sensibly. Then one person A can say: ‘There is an object X with properties Y.’ And another person B can say: ‘Yes, I agree.’
A certain object X with properties Y cannot be sensibly perceived by the involved persons. Then one person A can say: ‘The object X with properties Y is not there.’ And another person B can say: ‘Yes, I agree.’
There is an object with certain properties that the involved persons can perceive sensibly, which they have never seen before. Then one person A can say: ‘There is an object with properties, which I do not know yet. This is new to me.’ And another person B can then say: ‘Yes, I agree.’
A certain object X with properties Y cannot currently be sensibly perceived by the involved persons, but it was there before. Then one person A can say: ‘The object X with properties Y is no longer there.’ And another person B can say: ‘Yes, I agree.’
Introduction of Hypothesis 2 Case 1 becomes understandable if we assume that the sensory stimuli from object X with properties Y lead to activations in the sense organs, generating a sensory perception that can persist for the duration of object X’s presence.
To identify and classify this temporary perception as an ‘object of type X with properties Y,’ the involved persons must have a ‘memory’ that holds an ‘abstract object of type X with properties Y’ ready.
The ‘realized agreement’ between the perception of object X and the memory of a corresponding abstract object X then allows for the decision that there is a current perception of the abstract object X, whose ‘perceived properties’ ‘sufficiently match’ the ‘abstract properties.’
Important: this agreement occurring in the brain between a perceived object and a remembered object X does not imply anything about the real concrete circumstances that led to the perception of the object.[1]
This situation describes what is meant by Hypothesis 2: Persons can recognize a perceived object as an object of type X with properties Y if they have a memory available at the moment of the current perception.
Important: This Hypothesis 2 refers so far to what happens with and within an individual person. Another person normally cannot know about these processes. Internal processes in persons are — so far — not perceivable by others.[2]
[1] Modern simulation techniques can be so ‘real’ for most people that they make it difficult, if at all possible, to discern the ‘difference’ from the real world based solely on sensory perception. This would be the case where a sensory perception and a remembered abstract object in the brain show a substantial agreement, although there is no ‘real’ empirical object triggering the perception. … The computer itself, which ‘simulates’ something in a manner which looks for an observer ‘like being real’ (or the technical interface through which the computer’s signal reaches human sensors), is nevertheless a ‘real machine’ addressing the human sens organ ‘from the outside’.
[2] Even if modern neuroscientific measuring techniques can make electrical and chemical properties and activities visible, it is — so far — never possible to directly infer the functionalities hidden therein from these activities. Analogously, if one measures the electrical activities of the chips in a computer (which is possible and is done), one can never infer the algorithms currently being executed, even if one knows these algorithms!
Introduction of Hypothesis 3 Case 1 also includes the aspect that person A ‘verbally communicates’ something to person B. Without this verbal communication, B would know nothing about what is happening in A. In everyday life, a person usually perceives more than just one object, possibly many objects simultaneously. Therefore, knowing that a person is referring to a specific object and not one of the many other objects is not self-evident.
In Case 1, it should be stated: A person A says, “There is an object X with properties Y.” And another person B says, “Yes, I agree.”
When a person ‘says’ something that all participants recognize as ‘elements of language L,’ these elements of language L are ‘sounds,’ i.e., sound waves that are generated on one hand by a speaking organ (with a mouth) and received on the other side by an ‘ear.’ Let’s simply call the generating organ ‘actor’ and the receiving organ ‘sensor.’ Then, in verbal communication, a person produces sounds with an actor, and the participant of the communication receives these sounds through his sensor.
It is, of course, clear that the spoken and then also heard sounds of a language L have directly no relation to the internal processes of perception, remembering, and the ‘agreement process’ of perception and memory. However, it can be assumed that there must be ‘internal neural processes’ in the speaker and listener that must correspond to the generated sounds, otherwise the actor could not act.[1] In the case of the sensor, it was already pointed out earlier how stimuli from the outside world lead to activations of neurons, creating a flow of neural signals.
As it was generally assumed that there are neural signal flows and different abstract structures of objects that can be ‘internally’ stored and further processed, something similar must be assumed for the neural encoding of spoken and heard sounds. If one can distinguish elements and certain combinations of elements in the spoken acoustic sound material of a language, it is plausible to assume that these externally identifiable structures are also found in the internal neural realization.
The core idea of Hypothesis 3 can then be formulated as follows: There is a neural counterpart to the acoustically perceivable structure of a language L, which moreover is the ‘active’ part in producing spoken language and in ‘translating’ spoken sounds into the corresponding neural representations.
[1] The human speech organ is a highly complex system in which many systems work together, all of which must be neuronally controlled and coordinated.
Introduction of Hypothesis 4 With Hypothesis 2 (memory, comparison of perception and memory) and Hypothesis 3 (independent sound system of a language), the next Hypothesis 4 arises, suggesting that there must be some ‘relationship’ (mathematically: a mapping) between the sound system of a language L and the memorable objects along with current perception. This mapping allows ‘sounds’ to be connected with ‘objects (including properties)’ and vice versa.
In Case 1, person A has the perception of an object X with properties Y, along with a memory that ‘sufficiently matches,’ and person A says: “There is an object X with properties Y.” Another person B says, “Yes, I agree.”
Given the diversity of the world, constant changes, and the variety of possible sound systems [1], as well as the fact that humans undergo massive growth processes from embryo to continually developing person, it is unlikely that possible relationships between language sounds and perceived and remembered objects are ‘innate.’
This implies that this relationship (mapping) between language sounds and perceived and memorable objects must develop ‘over time,’ often referred to as ‘learning.’ Without certain presets, learning can be very slow; with available presets, it can be much faster. In the case of language learning, a person typically grows up in the presence of other people who generally already practice a language, which can serve as a reference system for growing individuals.
Language learning is certainly a lengthy process that includes not only individual acquisition but also inter-individual coordination among all those who practice a specific language L together.
As a result, learning a language means that not only is the ‘structure of the sound system’ learned, but also the association of elements of the sound system with elements of the perception-memory structure.[2]
In Case 1, therefore, person A must know which sound structure in the application group for language L is used for an object X with properties Y, and so must person B. If A and B have the same ‘relationship knowledge’ of sounds to objects and vice versa, person B can ‘understand’ the verbal expression of A “There is an object X with properties Y” because he also has a perception of this object and remembers an object X that sufficiently matches the perceived object, and he would name this fact in the same way A did. Then person B can say, “Yes, I agree.”
[1] Consider the many thousands of languages that still exist on planet Earth, where different languages can be used in the same living environment. The same ‘perception objects’ can thus be named differently depending on the language.
[2] The study of these matters has a long history with very, very many publications, but there is not yet a universally accepted unified theory.
Attention: This text has been translated from a German source by using the software deepL for nearly 97 – 99% of the text! The diagrams of the German version have been left out.
CONTEXT
This text represents the outline of a talk given at the conference “AI – Text and Validity. How do AI text generators change scientific discourse?” (August 25/26, 2023, TU Darmstadt). [1] A publication of all lectures is planned by the publisher Walter de Gruyter by the end of 2023/beginning of 2024. This publication will be announced here then.
Start of the Lecture
Dear Auditorium,
This conference entitled “AI – Text and Validity. How do AI text generators change scientific discourses?” is centrally devoted to scientific discourses and the possible influence of AI text generators on these. However, the hot core ultimately remains the phenomenon of text itself, its validity.
In this conference many different views are presented that are possible on this topic.
TRANSDISCIPLINARY
My contribution to the topic tries to define the role of the so-called AI text generators by embedding the properties of ‘AI text generators’ in a ‘structural conceptual framework’ within a ‘transdisciplinary view’. This helps the specifics of scientific discourses to be highlighted. This can then result further in better ‘criteria for an extended assessment’ of AI text generators in their role for scientific discourses.
An additional aspect is the question of the structure of ‘collective intelligence’ using humans as an example, and how this can possibly unite with an ‘artificial intelligence’ in the context of scientific discourses.
‘Transdisciplinary’ in this context means to span a ‘meta-level’ from which it should be possible to describe today’s ‘diversity of text productions’ in a way that is expressive enough to distinguish ‘AI-based’ text production from ‘human’ text production.
HUMAN TEXT GENERATION
The formulation ‘scientific discourse’ is a special case of the more general concept ‘human text generation’.
This change of perspective is meta-theoretically necessary, since at first sight it is not the ‘text as such’ that decides about ‘validity and non-validity’, but the ‘actors’ who ‘produce and understand texts’. And with the occurrence of ‘different kinds of actors’ – here ‘humans’, there ‘machines’ – one cannot avoid addressing exactly those differences – if there are any – that play a weighty role in the ‘validity of texts’.
TEXT CAPABLE MACHINES
With the distinction in two different kinds of actors – here ‘humans’, there ‘machines’ – a first ‘fundamental asymmetry’ immediately strikes the eye: so-called ‘AI text generators’ are entities that have been ‘invented’ and ‘built’ by humans, it are furthermore humans who ‘use’ them, and the essential material used by so-called AI generators are again ‘texts’ that are considered a ‘human cultural property’.
In the case of so-called ‘AI-text-generators’, we shall first state only this much, that we are dealing with ‘machines’, which have ‘input’ and ‘output’, plus a minimal ‘learning ability’, and whose input and output can process ‘text-like objects’.
BIOLOGICAL — NON-BIOLOGICAL
On the meta-level, then, we are assumed to have, on the one hand, such actors which are minimally ‘text-capable machines’ – completely human products – and, on the other hand, actors we call ‘humans’. Humans, as a ‘homo-sapiens population’, belong to the set of ‘biological systems’, while ‘text-capable machines’ belong to the set of ‘non-biological systems’.
BLANK INTELLIGENCE TERM
The transformation of the term ‘AI text generator’ into the term ‘text capable machine’ undertaken here is intended to additionally illustrate that the widespread use of the term ‘AI’ for ‘artificial intelligence’ is rather misleading. So far, there exists today no general concept of ‘intelligence’ in any scientific discipline that can be applied and accepted beyond individual disciplines. There is no real justification for the almost inflationary use of the term AI today other than that the term has been so drained of meaning that it can be used anytime, anywhere, without saying anything wrong. Something that has no meaning can be neither true’ nor ‘false’.
PREREQUISITES FOR TEXT GENERATION
If now the homo-sapiens population is identified as the original actor for ‘text generation’ and ‘text comprehension’, it shall now first be examined which are ‘those special characteristics’ that enable a homo-sapiens population to generate and comprehend texts and to ‘use them successfully in the everyday life process’.
VALIDITY
A connecting point for the investigation of the special characteristics of a homo-sapiens text generation and a text understanding is the term ‘validity’, which occurs in the conference topic.
In the primary arena of biological life, in everyday processes, in everyday life, the ‘validity’ of a text has to do with ‘being correct’, being ‘appicable’. If a text is not planned from the beginning with a ‘fictional character’, but with a ‘reference to everyday events’, which everyone can ‘check’ in the context of his ‘perception of the world’, then ‘validity in everyday life’ has to do with the fact that the ‘correctness of a text’ can be checked. If the ‘statement of a text’ is ‘applicable’ in everyday life, if it is ‘correct’, then one also says that this statement is ‘valid’, one grants it ‘validity’, one also calls it ‘true’. Against this background, one might be inclined to continue and say: ‘If’ the statement of a text ‘does not apply’, then it has ‘no validity’; simplified to the formulation that the statement is ‘not true’ or simply ‘false’.
In ‘real everyday life’, however, the world is rarely ‘black’ and ‘white’: it is not uncommon that we are confronted with texts to which we are inclined to ascribe ‘a possible validity’ because of their ‘learned meaning’, although it may not be at all clear whether there is – or will be – a situation in everyday life in which the statement of the text actually applies. In such a case, the validity would then be ‘indeterminate’; the statement would be ‘neither true nor false’.
ASYMMETRY: APPLICABLE- NOT APPLICABLE
One can recognize a certain asymmetry here: The ‘applicability’ of a statement, its actual validity, is comparatively clear. The ‘not being applicable’, i.e. a ‘merely possible’ validity, on the other hand, is difficult to decide.
With this phenomenon of the ‘current non-decidability’ of a statement we touch both the problem of the ‘meaning’ of a statement — how far is at all clear what is meant? — as well as the problem of the ‘unfinishedness of our everyday life’, better known as ‘future’: whether a ‘current present’ continues as such, whether exactly like this, or whether completely different, depends on how we understand and estimate ‘future’ in general; what some take for granted as a possible future, can be simply ‘nonsense’ for others.
MEANING
This tension between ‘currently decidable’ and ‘currently not yet decidable’ additionally clarifies an ‘autonomous’ aspect of the phenomenon of meaning: if a certain knowledge has been formed in the brain and has been made usable as ‘meaning’ for a ‘language system’, then this ‘associated’ meaning gains its own ‘reality’ for the scope of knowledge: it is not the ‘reality beyond the brain’, but the ‘reality of one’s own thinking’, whereby this reality of thinking ‘seen from outside’ has something like ‘being virtual’.
If one wants to talk about this ‘special reality of meaning’ in the context of the ‘whole system’, then one has to resort to far-reaching assumptions in order to be able to install a ‘conceptual framework’ on the meta-level which is able to sufficiently describe the structure and function of meaning. For this, the following components are minimally assumed (‘knowledge’, ‘language’ as well as ‘meaning relation’):
KNOWLEDGE: There is the totality of ‘knowledge’ that ‘builds up’ in the homo-sapiens actor in the course of time in the brain: both due to continuous interactions of the ‘brain’ with the ‘environment of the body’, as well as due to interactions ‘with the body itself’, as well as due to interactions ‘of the brain with itself’.
LANGUAGE: To be distinguished from knowledge is the dynamic system of ‘potential means of expression’, here simplistically called ‘language’, which can unfold over time in interaction with ‘knowledge’.
MEANING RELATIONSHIP: Finally, there is the dynamic ‘meaning relation’, an interaction mechanism that can link any knowledge elements to any language means of expression at any time.
Each of these mentioned components ‘knowledge’, ‘language’ as well as ‘meaning relation’ is extremely complex; no less complex is their interaction.
FUTURE AND EMOTIONS
In addition to the phenomenon of meaning, it also became apparent in the phenomenon of being applicable that the decision of being applicable also depends on an ‘available everyday situation’ in which a current correspondence can be ‘concretely shown’ or not.
If, in addition to a ‘conceivable meaning’ in the mind, we do not currently have any everyday situation that sufficiently corresponds to this meaning in the mind, then there are always two possibilities: We can give the ‘status of a possible future’ to this imagined construct despite the lack of reality reference, or not.
If we would decide to assign the status of a possible future to a ‘meaning in the head’, then there arise usually two requirements: (i) Can it be made sufficiently plausible in the light of the available knowledge that the ‘imagined possible situation’ can be ‘transformed into a new real situation’ in the ‘foreseeable future’ starting from the current real situation? And (ii) Are there ‘sustainable reasons’ why one should ‘want and affirm’ this possible future?
The first requirement calls for a powerful ‘science’ that sheds light on whether it can work at all. The second demand goes beyond this and brings the seemingly ‘irrational’ aspect of ’emotionality’ into play under the garb of ‘sustainability’: it is not simply about ‘knowledge as such’, it is also not only about a ‘so-called sustainable knowledge’ that is supposed to contribute to supporting the survival of life on planet Earth — and beyond –, it is rather also about ‘finding something good, affirming something, and then also wanting to decide it’. These last aspects are so far rather located beyond ‘rationality’; they are assigned to the diffuse area of ’emotions’; which is strange, since any form of ‘usual rationality’ is exactly based on these ’emotions’.[2]
SCIENTIFIC DISCOURSE AND EVERYDAY SITUATIONS
In the context of ‘rationality’ and ’emotionality’ just indicated, it is not uninteresting that in the conference topic ‘scientific discourse’ is thematized as a point of reference to clarify the status of text-capable machines.
The question is to what extent a ‘scientific discourse’ can serve as a reference point for a successful text at all?
For this purpose it can help to be aware of the fact that life on this planet earth takes place at every moment in an inconceivably large amount of ‘everyday situations’, which all take place simultaneously. Each ‘everyday situation’ represents a ‘present’ for the actors. And in the heads of the actors there is an individually different knowledge about how a present ‘can change’ or will change in a possible future.
This ‘knowledge in the heads’ of the actors involved can generally be ‘transformed into texts’ which in different ways ‘linguistically represent’ some of the aspects of everyday life.
The crucial point is that it is not enough for everyone to produce a text ‘for himself’ alone, quite ‘individually’, but that everyone must produce a ‘common text’ together ‘with everyone else’ who is also affected by the everyday situation. A ‘collective’ performance is required.
Nor is it a question of ‘any’ text, but one that is such that it allows for the ‘generation of possible continuations in the future’, that is, what is traditionally expected of a ‘scientific text’.
From the extensive discussion — since the times of Aristotle — of what ‘scientific’ should mean, what a ‘theory’ is, what an ’empirical theory’ should be, I sketch what I call here the ‘minimal concept of an empirical theory’.
The starting point is a ‘group of people’ (the ‘authors’) who want to create a ‘common text’.
This text is supposed to have the property that it allows ‘justifiable predictions’ for possible ‘future situations’, to which then ‘sometime’ in the future a ‘validity can be assigned’.
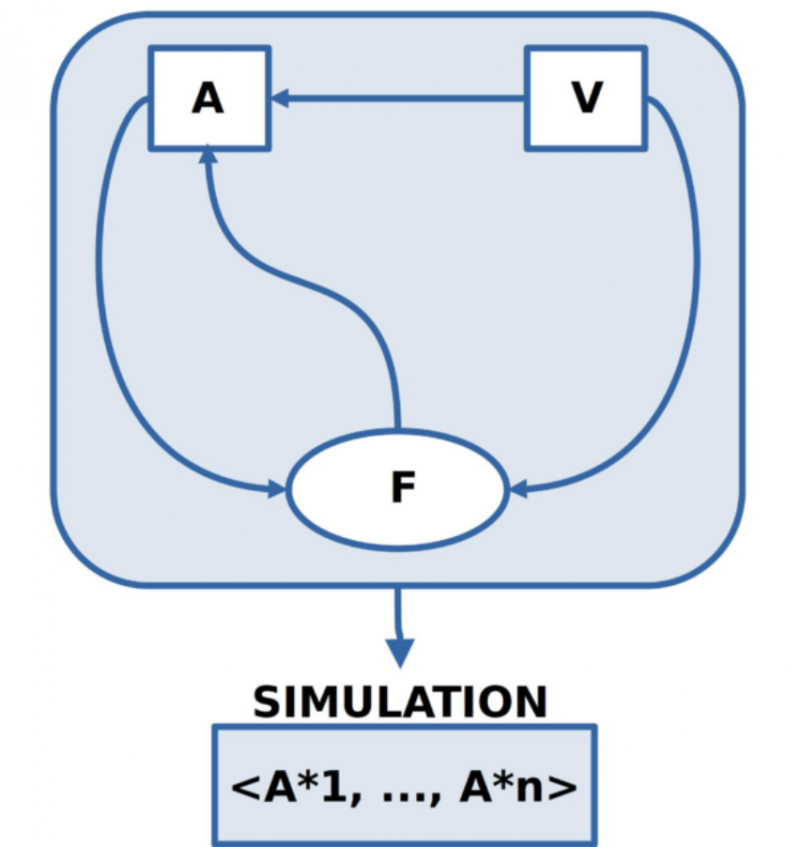
The authors are able to agree on a ‘starting situation’ which they transform by means of a ‘common language’ into a ‘source text’ [A].
It is agreed that this initial text may contain only ‘such linguistic expressions’ which can be shown to be ‘true’ ‘in the initial situation’.
In another text, the authors compile a set of ‘rules of change’ [V] that put into words ‘forms of change’ for a given situation.
Also in this case it is considered as agreed that only ‘such rules of change’ may be written down, of which all authors know that they have proved to be ‘true’ in ‘preceding everyday situations’.
The text with the rules of change V is on a ‘meta-level’ compared to the text A about the initial situation, which is on an ‘object-level’ relative to the text V.
The ‘interaction’ between the text V with the change rules and the text A with the initial situation is described in a separate ‘application text’ [F]: Here it is described when and how one may apply a change rule (in V) to a source text A and how this changes the ‘source text A’ to a ‘subsequent text A*’.
The application text F is thus on a next higher meta-level to the two texts A and V and can cause the application text to change the source text A.
The moment a new subsequent text A* exists, the subsequent text A* becomes the new initial text A.
If the new initial text A is such that a change rule from V can be applied again, then the generation of a new subsequent text A* is repeated.
This ‘repeatability’ of the application can lead to the generation of many subsequent texts <A*1, …, A*n>.
A series of many subsequent texts <A*1, …, A*n> is usually called a ‘simulation’.
Depending on the nature of the source text A and the nature of the change rules in V, it may be that possible simulations ‘can go quite differently’. The set of possible scientific simulations thus represents ‘future’ not as a single, definite course, but as an ‘arbitrarily large set of possible courses’.
The factors on which different courses depend are manifold. One factor are the authors themselves. Every author is, after all, with his corporeality completely himself part of that very empirical world which is to be described in a scientific theory. And, as is well known, any human actor can change his mind at any moment. He can literally in the next moment do exactly the opposite of what he thought before. And thus the world is already no longer the same as previously assumed in the scientific description.
Even this simple example shows that the emotionality of ‘finding good, wanting, and deciding’ lies ahead of the rationality of scientific theories. This continues in the so-called ‘sustainability discussion’.
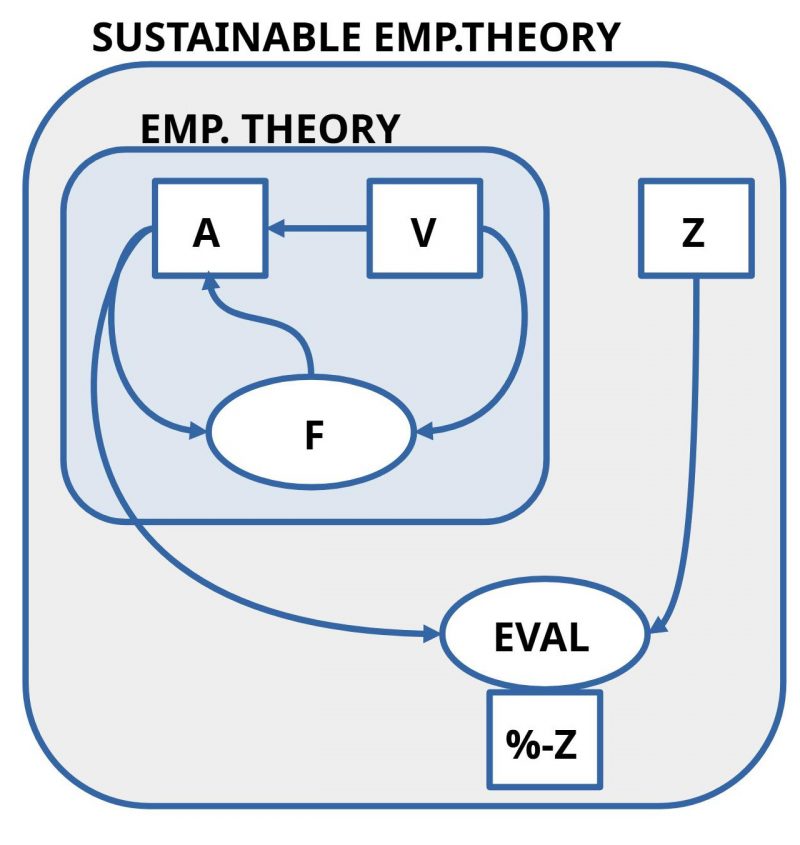
SUSTAINABLE EMPIRICAL THEORY
With the ‘minimal concept of an empirical theory (ET)’ just introduced, a ‘minimal concept of a sustainable empirical theory (NET)’ can also be introduced directly.
While an empirical theory can span an arbitrarily large space of grounded simulations that make visible the space of many possible futures, everyday actors are left with the question of what they want to have as ‘their future’ out of all this? In the present we experience the situation that mankind gives the impression that it agrees to destroy the life beyond the human population more and more sustainably with the expected effect of ‘self-destruction’.
However, this self-destruction effect, which can be predicted in outline, is only one variant in the space of possible futures. Empirical science can indicate it in outline. To distinguish this variant before others, to accept it as ‘good’, to ‘want’ it, to ‘decide’ for this variant, lies in that so far hardly explored area of emotionality as root of all rationality.[2]
If everyday actors have decided in favor of a certain rationally lightened variant of possible future, then they can evaluate at any time with a suitable ‘evaluation procedure (EVAL)’ how much ‘percent (%) of the properties of the target state Z’ have been achieved so far, provided that the favored target state is transformed into a suitable text Z.
In other words, the moment we have transformed everyday scenarios into a rationally tangible state via suitable texts, things take on a certain clarity and thereby become — in a sense — simple. That we make such transformations and on which aspects of a real or possible state we then focus is, however, antecedent to text-based rationality as an emotional dimension.[2]
MAN-MACHINE
After these preliminary considerations, the final question is whether and how the main question of this conference, “How do AI text generators change scientific discourse?” can be answered in any way?
My previous remarks have attempted to show what it means for humans to collectively generate texts that meet the criteria for scientific discourse that also meets the requirements for empirical or even sustained empirical theories.
In doing so, it becomes apparent that both in the generation of a collective scientific text and in its application in everyday life, a close interrelation with both the shared experiential world and the dynamic knowledge and meaning components in each actor play a role.
The aspect of ‘validity’ is part of a dynamic world reference whose assessment as ‘true’ is constantly in flux; while one actor may tend to say “Yes, can be true”, another actor may just tend to the opposite. While some may tend to favor possible future option X, others may prefer future option Y. Rational arguments are absent; emotions speak. While one group has just decided to ‘believe’ and ‘implement’ plan Z, the others turn away, reject plan Z, and do something completely different.
This unsteady, uncertain character of future-interpretation and future-action accompanies the Homo Sapiens population from the very beginning. The not understood emotional complex constantly accompanies everyday life like a shadow.
Where and how can ‘text-enabled machines’ make a constructive contribution in this situation?
Assuming that there is a source text A, a change text V and an instruction F, today’s algorithms could calculate all possible simulations faster than humans could.
Assuming that there is also a target text Z, today’s algorithms could also compute an evaluation of the relationship between a current situation as A and the target text Z.
In other words: if an empirical or a sustainable-empirical theory would be formulated with its necessary texts, then a present algorithm could automatically compute all possible simulations and the degree of target fulfillment faster than any human alone.
But what about the (i) elaboration of a theory or (ii) the pre-rational decision for a certain empirical or even sustainable-empirical theory ?
A clear answer to both questions seems hardly possible to me at the present time, since we humans still understand too little how we ourselves collectively form, select, check, compare and also reject theories in everyday life.
My working hypothesis on the subject is: that we will very well need machines capable of learning in order to be able to fulfill the task of developing useful sustainable empirical theories for our common everyday life in the future. But when this will happen in reality and to what extent seems largely unclear to me at this point in time.[2]
COMMENTS
[1] https://zevedi.de/en/topics/ki-text-2/
[2] Talking about ’emotions’ in the sense of ‘factors in us’ that move us to go from the state ‘before the text’ to the state ‘written text’, that hints at very many aspects. In a small exploratory text “State Change from Non-Writing to Writing. Working with chatGPT4 in parallel” ( https://www.uffmm.org/2023/08/28/state-change-from-non-writing-to-writing-working-with-chatgpt4-in-parallel/ ) the author has tried to address some of these aspects. While writing it becomes clear that very many ‘individually subjective’ aspects play a role here, which of course do not appear ‘isolated’, but always flash up a reference to concrete contexts, which are linked to the topic. Nevertheless, it is not the ‘objective context’ that forms the core statement, but the ‘individually subjective’ component that appears in the process of ‘putting into words’. This individual subjective component is tentatively used here as a criterion for ‘authentic texts’ in comparison to ‘automated texts’ like those that can be generated by all kinds of bots. In order to make this difference more tangible, the author decided to create an ‘automated text’ with the same topic at the same time as the quoted authentic text. For this purpose he used chatGBT4 from openAI. This is the beginning of a philosophical-literary experiment, perhaps to make the possible difference more visible in this way. For purely theoretical reasons, it is clear that a text generated by chatGBT4 can never generate ‘authentic texts’ in origin, unless it uses as a template an authentic text that it can modify. But then this is a clear ‘fake document’. To prevent such an abuse, the author writes the authentic text first and then asks chatGBT4 to write something about the given topic without chatGBT4 knowing the authentic text, because it has not yet found its way into the database of chatGBT4 via the Internet.
In a preceding post I have illustrated how one can apply the concept of an empirical theory — highly inspired by Karl Popper — to an everyday problem given as a county and its demographic problem(s). In this post I like to develop this idea a little more.
AN EMPIRICAL THEORY AS A DEVELOPMENT PROCESS
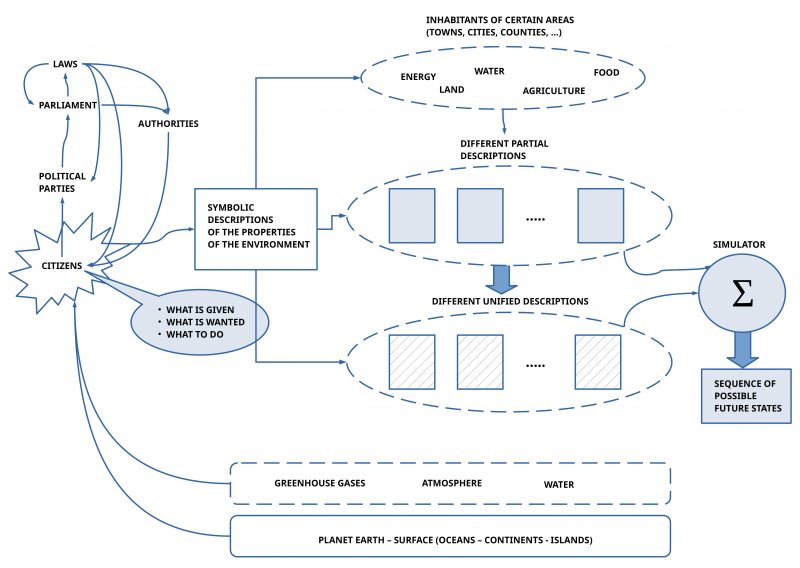
The figure shows a simplified outline of the idea of an empirical theory being realized during a development process based on the interactions and the communication of citizens as ‘natural experts’.
CITIZENs – natural experts
As starting point we assume citizens understood as our ‘natural experts’ being members of a democratic society with political parties, an freely elected parliament, which can create some helpful laws for the societal life and some authorities serving the need of the citizens.
SYMBOLIC DESCRIPTIONS
To coordinate their actions by a sufficient communication the citizens produce symbolic descriptions to make public how they see the ‘given situation’, which kinds of ‘future states’ (‘goals’) they want to achieve, and a list of ‘actions’ which can ‘change/ transform’ the given situation step wise into the envisioned future state.
LEVELS OF ABSTRACTIONS
Using an everyday language — possibly enriched with some math expressions – one can talk about our world of experience on different levels of abstraction. To get a rather wide scope one starts with most abstract concepts, and then one can break down these abstract concepts more and more with concrete properties/ features until these concrete expressions are ‘touching the real experience’. It can be helpful — in most cases — not to describe everything in one description but one does a partition of ‘the whole’ into several more concrete descriptions to get the main points. Afterwards it should be possible to ‘unify’ these more concrete descriptions into one large picture showing how all these concrete descriptions ‘work together’.
LOGICAL INFERENCE BY SIMULATION
A very useful property of empirical theories is the possibility to derive from given assumptions and assumed rules of inference possible consequences which are ‘true’ if the assumptions an the rules of inference are ‘true’.
The above outlined descriptions are seen in this post as texts which satisfy the requirements of an empirical theory such that the ‘simulator’ is able to derive from these assumptions all possible ‘true’ consequences if these assumptions are assumed to be ‘true’. Especially will the simulator deliver not only one single consequence only but a whole ‘sequence of consequences’ following each other in time.
PURE WWW KNOWLEDGE SPACE
This simple outline describes the application format of the oksimo software which is understood here as a kind of a ‘theory machine’ for everybody.
It is assumed that a symbolic description is given as a pure text file or as a given HTML page somewhere in the world wide web [WWW].
The simulator realized as an oksimo program can load such a file and can run a simulation. The output will be send back as an HTML page.
No special special data base is needed inside of the oksimo application. All oksimo related HTML pages located by a citizen somewhere in the WWW are constituting a ‘global public knowledge space’ accessible by everybody.
DISTRIBUTED OKSIMO INSTANCES
An oksimo server positioned behind the oksimo address ‘oksimo.com’ can produce for a simulation demand a ‘simulator instance’ running one simulation. There can be many simulations running in parallel. A simulation can also be connected in real time to Internet-of-Things [IoT] instances to receive empirical data being used in the simulation. In ‘interactive mode’ an oksimo simulation does furthermore allow the participation of ‘actors’ which function as a ‘dynamic rule instance’: they receive input from the simulated given situation and can respond ‘on their own’. This turns a simulation into an ‘open process’ like we do encounter during ‘everyday real processes’. An ‘actor’ must not necessarily be a ‘human’ actor; it can also be a ‘non-human’ actor. Furthermore it is possible to establish a ‘simulation-meta-level’: because a simulation as a whole represents a ‘full theory’ on can feed this whole theory to an ‘artificial intelligence algorithm’ which dos not run only one simulation but checks the space of ‘all possible simulations’ and thereby identifies those sub-spaces which are — according to the defined goals — ‘zones of special interest’.
This post shows a simple simulation example with the beta-version of the new Version 2 of the oksimo programming environment. This example shall illustrate the concept of an ‘Everyday Empirical Theory‘ as described in this blog 11 days before. It is intentionally as ‘simple as possible’. Probably some more examples will be shown.
FROM THEORY TO AN APPLICATION
To apply a theory concept in an everyday world there are many formats possible. In this text it will be shown how such an application would look like if one is applying the oksimo programming environment. Until now there exists only a German Blog (oksimo.org) describing the oksimo paradigm a little bit. But the examples there are written with oksimo version 1, which didn’t allow to use math. In version 2 this is possible, accompanied by some visual graph features.
Everyday Experts – Basic Ideas
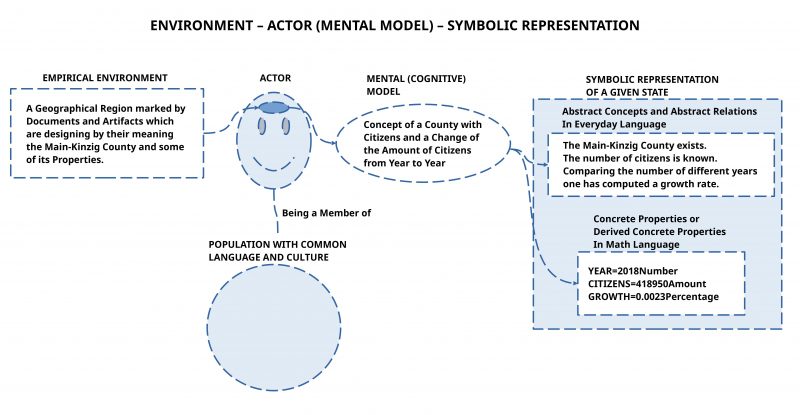
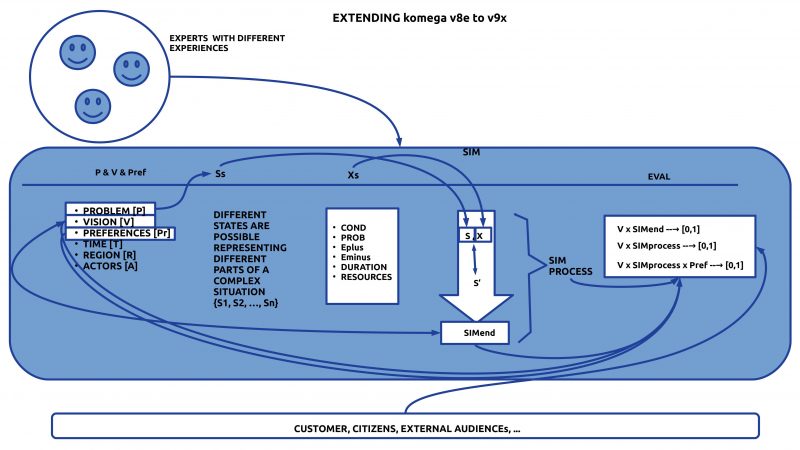
This figure shows a simple outline of the basic assumptions of the oksimo programming environment constituting the oksimo paradigm: (i) Every human person is assumed to be a ‘natural expert’ being member of a bigger population which shares the same ‘everyday language’ including basic math. (ii) An actor is embedded in some empirical environment including the own body and other human actors. (iii) Human actors are capable of elaborating as inner states different kinds of ‘mental (cognitive) models’ based on their experience of the environment and their own body. (iv) Human actors are further capable to use symbolic languages to ‘represent’ properties of these mental models encoded in symbolic expressions. Such symbolic encoding presupposes an ‘inner meaning function’ which has to be learned. (v) In the oksimo programming environment one needs for the description of a ‘given state’ two kinds of symbolic expressions: (v.1) Language expressions to describe general properties and relations which are assumed to be ‘given’ (= ‘valid by experience’); (v.2) Language expressions to name concrete quantitative properties (simple math expressions).This figure shows the idea how to change a given state (situation) by so-called ‘change rules’. A change rule encodes experience from the everyday world under which conditions some properties of a given situation S can be ‘changed’ in a way, that a ‘new situation’ S* comes into being. Generally a given state can change if either language expression is ‘deleted’ from the description or ‘contributed’. Another possibility is realized if one of the given quantitative expressions changes its value. In the above simple situation the only change happens by changing the number of citizens by some growth effect. But, as other examples will demonstrate, everything is possible what is possible in the empirical world.
SOME MORE FEATURES
The basic schema of the oksimo paradigm assumes the following components:
The description of a ‘given situation’ as a ‘start state’.
The description of a ‘vision’ functioning as a ‘goal’ which allows a basic ‘Benchmarking’.
A list of ‘change rules’ which describe the assumed possible changes
An ‘inference engine’ called ‘simulator’: Depending from the number of wanted ‘simulation cycles’ (‘inferences’) the simulator applies the change rules onto a given state S and thereby it is producing a ‘follow up state’ S*, which becomes the new given state. The series of generated states represents the ‘history’ of a simulation. Every follow up state is an ‘inference’ and by definition also a ‘forecast’.
All these features (1) – (4) together constitute a full empirical theory in the sense of the mentioned theory post before.
Let us look to a real simulation.
A REAL SIMULATION
The following example has been run with Oksimo v2.0 (Pre-Release) (353e5). Hopefully we can finish the pre-release to a full release the next few weeks.
A VISION
Name: v2026
Expressions:
The Main-Kinzig County exists.
Math expressions:
YEAR>2025 and YEAR<2027
This simple goal assumes the existence of the Main-Kinzig County for the year 2026.
GIVEN START STATE
Name: StartSimple1
Expressions:
The Main-Kinzig County exists.
The number of citizens is known.
Comparing the number of different years one has computed a growth rate.
Math expressions:
YEAR=2018Number
CITIZENS=418950Amount
GROWTH=0.0023Percentage
The start state makes some simple statements which are assumed to be ‘valid’ in a ‘real given situation’ by the participating natural experts.
CHANGE RULES
In this example there is only one change rules (In principle there can be as many change rules as wanted).
Rule name: Growth1
Probability: 1.0
Conditions:
The Main-Kinzig County exists.
Math conditions:
CITIZENS < 450000
Effects plus:
Effects minus:
Effects math:
CITIZENS=CITIZENS+(CITIZENS*GROWTH)
YEAR=YEAR+1
This change rules is rather simple. It looks only to the fact whether the Main-Kinzig County exists and wether the number of citizens is still below 450000. If this is the case, then the year will be incremented and the number of citizens will be incremented according to an extremely simple formula.
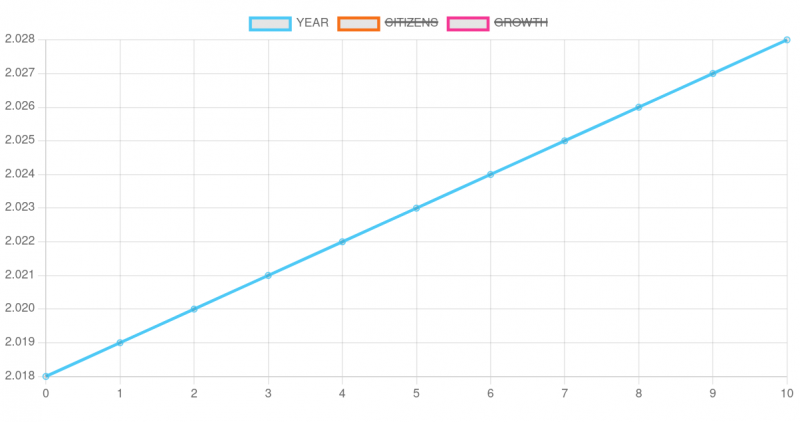
For every named quantity in this simulation (YEAR, GROWTH, CITIZENS) the values are collected for every simulation cycle and therefore can be used for evaluations. In this simple case only the quantities of YEAR and CITIZENS have changes:
Simple linear graph for the quantity named YEARSimple linear graph for the quantity named CITIZENS
Here the quick log of simulation cycle round 7 – 9:
Round 7
State rules:
Vision rules:
Current states: The number of citizens is known.,Comparing the number of different years one has computed a growth rate.,The Main-Kinzig County exists.
Current visions: The Main-Kinzig County exists.
Current values:
YEAR: 2025Number
CITIZENS: 425741.8149741673Amount
GROWTH: 0.0023Percentage
50.00 percent of your vision was achieved by reaching the following states:
The Main-Kinzig County exists.,
And the following math visions:
None
Round 8
State rules:
Vision rules:
Current states: The number of citizens is known.,Comparing the number of different years one has computed a growth rate.,The Main-Kinzig County exists.
Current visions: The Main-Kinzig County exists.
Current values:
YEAR: 2026Number
CITIZENS: 426721.0211486079Amount
GROWTH: 0.0023Percentage
100.00 percent of your vision was achieved by reaching the following states:
The Main-Kinzig County exists.,
And the following math visions:
YEAR>2025 and YEAR<2027,
Round 9
State rules:
Vision rules:
Current states: The number of citizens is known.,Comparing the number of different years one has computed a growth rate.,The Main-Kinzig County exists.
Current visions: The Main-Kinzig County exists.
Current values:
YEAR: 2027Number
CITIZENS: 427702.4794972497Amount
GROWTH: 0.0023Percentage
50.00 percent of your vision was achieved by reaching the following states:
The Main-Kinzig County exists.,
And the following math visions:
None
In round 8 one can see, that the simulation announces:
“100.00 percent of your vision was achieved by reaching the following states: The Main-Kinzig County exists., And the following math visions: YEAR>2025 and YEAR<2027“
From this the natural expert can conclude that his requirements given in the vision are ‘fulfilled’/’satisfied’.
WHAT COMES NEXT?
In a loosely order more examples will follow. Here you find the next one.
This text is part of a philosophy of science analysis of the case of the oksimo software (oksimo.com). A specification of the oksimo software from an engineering point of view can be found in four consecutive posts dedicated to the HMI-Analysis for this software.
DERIVATION
In formal logic exists the concept of logical derivation ‘⊢’ written as
E ⊢X e
saying that one can get the expression e out of the set of expressions E by applying the rules X.
In the oksimo case we have sets of expressions ES to represent either a given starting state S or to represent as EV a given vision V. Furthermore we have change rules X operating on sets of expressions and we can derive sequences of states of expressions <E1, E2, …, En> by applying the change rules X with the aid of a simulator Σ onto these expressions written as
ES ⊢Σ,X <E1, E2, …, En>
Thus given an initial set of expressions ES one can derive a whole sequence of expression sets Ei by applying the change rules.
While all individual expressions of the start set ES are by assumption classified as true it holds for the derived sets of expressions Ei that these expressions are correct with regard to the used change rulesX but whether these sets of expressions are also true with regard to a given situation Si considered as a possible future state Sfutihas to be proved separately! The reason for this unclear status results from the fact that the change rules X represent changes which the authoring experts consider as possible changes which they want to apply but they cannot guarantee the empirical validity for all upcoming times only by thinking. This implicit uncertainty can be handled a little bit with the probability factor π of an individual change rule. The different degrees of certainty in the application of a change rule can give an approximation of this uncertainty. Thus as longer the chain of derivations is becoming as lower the assumed probability will develop.
SIMPLE OKSIMO THEORY [TOKSIMO]
Thus if we have some human actors Ahum, an environment ENV, some starting situation S as part of the environment ENV, a first set of expressions ES representing only true expressions with regard to the starting situation S, a set of elaborated change rules X, and a simulator Σ then one can define a simple oksimo-like theory Toksimo as follows:
The human actors can describe a given situation S as part of an environment ENV as a set of expressions ES which can be proved with makedecidable() as true. By defining a set of change rules X and a simulator Σ one can define a formal derivation relation ⊢Σ,X which allows the derivation of a sequence of sets of expressions <E1, E2, …, En> written as
ES ⊢T,Σ,X <E1, E2, …, En>
While the truth of the first set of expressions ES has been proved in the beginning, the truth of the derived sets of expressions has to be shown explicitly for each set Ei separately. Given is only the formal correctness of the derived expressions according to the change rules X and the working of the simulator.
VALIDADED SIMPLE OKSIMO THEORY [TOKSIMO.V]
One can extend the simple oksimo theory TOKSIMO to a biased oksimo theory TOKSIMO.V if one includes in the theory a set of vision expressions EV. Vision expressions can describe a possible situation in the future Sfut which is declared as a goal to be reached. With a given vision document EV the simulator can check for every new derived set of expressions Ei to which degree the individual expressions e of the set of vision expressions EV are already reached.
FROM THEORY TO ENGINEERING
But one has to keep in mind that the purely formal achievement of a given vision document EV does not imply that the corresponding situation Sfut is a real situation. The corresponding situation Sfut is first of all only an idea in the mind of the experts. To transfer this idea into the real environment as a real situation is a process on its own known as engineering.
This text is part of a philosophy of science analysis of the case of the oksimo software (oksimo.com). A specification of the oksimo software from an engineering point of view can be found in four consecutive posts dedicated to the HMI-Analysis for this software.
CHANGE
AS described in part 1 of the philosophy of science analysis of the oksimo behavior space it is here assumed — following the ideas of von Uexküll — that every biological species SP embedded in a real environment ENV transforms this environment in its species specific internal representation ENVSP which is no 1-to-1 mapping. Furthermore we know from modern Biology and brain research that the human brain cuts its sensory perceptions P into time-slices P1, P2, … which have durations between about 50 – 700 milliseconds and which are organized as multi-modal structures for further processing. The results of this processing are different kinds of abstracted structures which represent — not in a 1-to-1 fashion — different aspects of a given situation S which in the moment of being processed and then being stored is not any longer actual, ‘not now’, but ‘gone‘, ‘past‘.
Thus if we as human actors are speaking about change then we are primarily speaking about the difference which our brain can compute comparing the actual situation S being kept in an actual time-slice P0 and those abstracted structures A(P) coming out of preceding time slices interacting in many various ways with other available abstracted structures: Diff(A(P0), A(P)) = Δint. Usually we assumeautomatically that the perceived internal change Δint corresponds to a change in the actual situation S leading to a follow-up situation S’ which differs with regard to the species specific perception represented in Δint as Δext = Diff(S, S’). As psychological tests can reveal this automatic (unconscious) assumption that a perceived change Δint corresponds to a real external change Δextmust not be the case. There is a real difference between Δint,Δext and on account of this difference there exists the possibility that we can detect an error comparing our ideas with the real world environment. Otherwise — in the absence of an error — a congruence can be interpreted as a confirmation of our ideas.
EXPRESSIONS CAN FOLLOW REAL PROPERTIES
As described in the preceding posts about a decidable start state S and a vision V it is possible to map a perceived actual situation S in a set of expressions ES={e1, e2, …, en }. This general assumption is valid for all real states S, which results in the fact that a series of real states S1, S2, …, Sn is conceivable where every such real state Si can be associated with a set of expressions Ei which contain individual expressions ei which represent according to the presupposed meaning function φ certain aspects/ properties Pi of the corresponding real situation Si. Thus, if two consecutive real states Si, Si+1 are include perceived differences indicated by some properties then it is possible to express these differences by corresponding expressions ei as part of the whole set of expressions Ei and Ei+1. If e.g. in the successor of Si one property px expressed by ex is missing which is present in Si then the corresponding set Ei+1 should not include the expression ex. Or if the successor state Si+1 contains a property py expressed by the expression ey which is not yet given in Si then this fact too indicates a difference. Thus the differing pair (Si, Si+1) could correspond to the pair (Ei, Ei+1) with ex as part of Ei but not any more in Ei+1 and the expression ey not part of Ei but then in Ei+1.
The general schema could be described as:
Si+1 = Si -{px} + {py} (the real dimension)
Ei+1 = Ei – {ex} + {ey} (the symbolic dimension)
Between the real dimension and the symbolic dimension is the body with the brain offering all the neural processing which is necessary to enable such complex mappings. This can bne expressed by the following pragmatic recipe:
symbolicarticulation: S x body[brain] —> E
symbolicarticulation(S,body[brain]) = E
Having a body with a brain embedded in an actual (real) situation S the body (with the brain) can produce symbolic expressions corresponding to certain properties of the situation S.
DESCRIBING CHANGE
Assuming that symbolic articulation is possible and that there is some regular mapping between an actual situation S and a set of expressions E it is conceivable to describe the generation of two successive actual states S, S’ as follows:
Apply a Change Rule ξ of X
We have a given actual situation S.
We have a group of human actors Ahum which are using a language L.
The group generates a decidable description of S as a set of expressions ELS following the rules of language L.
Thus we have symbolicarticulation(S, Ahum) = ELS
The group of human actors defines a finite set of change rules X which describe which expressions Eminus should be removed from ES and which expressions Eplus should be added to ES to get the successor state ES‘ represented in a symbolic space:
ES‘ = ES – Eminus + Eplus . An individual change rule ξ of X has the format:
IF COND THEN with probability π REMOVE Eminus and ADD Eplus.
COND is a set of expressions which shall be a subset of the given set ES saying: COND ⊆ ES. If this condition is satisfied (fulfilled) then the rule can be applied following probability π.
Thus applying a change rule ξ to a given state S means to operate on the corresponding set of expressions ES of S as follows:
applychange: S x ES x {ξ} —> ES‘
There can be more than only one change rule ξ as a finite set X = {ξ1, ξ2, …, ξn}. They have all to be applied in a random order. Thus we get:
applychange: S x ES x X —> ES‘ or applychange(S,ES,X) = ES‘
Simulation
If one has a given actual state S with a finite set of change rules X we know now how to apply this finite set of change rules X to a given state description ES. But if we would enlarge the set of change rules X in a way that this set X* not only contains rules for the given actual state description ES but also for a finite number of other possible state descriptions ES* then one could repeat the application of the change rules X* several times by using the last outcome desribing ES‘ to make ES‘ to the new actual state description ES. Proceeding in this way we can generate a whole sequence of state decriptions: <ES.0, ES.1, …, ES.n> where for each pair (ES.i, ES.i+1) it holds that applychange(Si,ES.i,X) = ES.i+1
Such a repetitive application of the applychange() rule we call here a simulation: S x ES x X —> <ES.0, ES.1, …, ES.n> with the condition for each pair (ES.i, ES.i+1) that it holds that applychange(Si,ES.i,X) = ES.i+1also written as: simulation(S , ES, X) = <ES.0, ES.1, …, ES.n>.
A device which can operate a simulation is called a simulator ∑. A simulator is either a human actor or a computer with an appropriate algorithm.
Integrating Engineering and the Human Factor (info@uffmm.org)
eJournal uffmm.org ISSN 2567-6458, March 2, 2021,
Author: Gerd Doeben-Henisch
Email: gerd@doeben-henisch.de
Last change: March 2, 2021 13:59h (Minor corrections)
Having a vision is that moment where something really new in the whole universe is getting an initial status in some real brain which can enable other neural events which can possibly be translated in bodily events which finally canchange the body-external outside world. If this possibility is turned into reality than the outside world has been changed.
When human persons (groups of homo sapiens specimens) as experts — here acting as stakeholder and intended users as one but in different roles! — have stated a problem and a vision document, then they have to translate these inevitably more fuzzy than clear ideas into the concrete terms of an everyday world, into something which can really work.
To enable a real cooperation the experts have to generate a symbolic description of their vision (called specification) — using an everyday language, possibly enhanced by special expressions — in a way that it can became clear to the whole group, which kind of real events, actions and processes are intended.
In the general case an engineering specification describes concrete forms of entanglements of human persons which enable these human persons to cooperate in a real situation. Thereby the translation of the vision inside the brain into the everyday body-external reality happens. This is the language of life in the universe.
WRITING A STORY
To elaborate a usable specification can metaphorically be understood as the writing of a new story: which kinds of actors will do something in certain situations, what kinds of other objects, instruments etc. will be used, what kinds of intrinsicmotivations and experiences are pushing individual actors, what are possible outcomes of situations with certain actors, which kind of cooperation is helpful, and the like. Such a story is called here Actor Story [AS].
COULD BE REAL
An Actor Story must be written in a way, that all participating experts can understand the language of the specification in a way that the content, the meaning of the specification is either decidable real or that it eventually can become real. At least the starting point of the story should be classifiable as being decidable actual real. What it means to be decidable actual real has to be defined and agreed between the participating experts before they start writing the Actor Story.
ACTOR STORY [AS]
An Actor Story assumes that the described reality is classifiable as a set of situations (states) and a situation as part of the Actor Story — abbreviated: situationAS — is understood as a set of expressions of some everyday language. Every expression being part of an situationAS can be decided as being real (= being true) in the understood real situation.
If the understood real situation is changing (by some event), then the describing situationAS has to be changed too; either some expressions have to be removed or have to be added.
Every kind of change in the real situation S* has to be represented in the actor story with the situationAS S symbolically in the format of a change rule:
X: If condition C is satisfied in S then with probability π add to S Eplus and remove from S Eminus.
or as a formula:
S’π = S + Eplus – Eminus
This reads as follows: If there is an situationAS S and there is a change rule X, then you can apply this change rule X with probability π onto S if the condition of X is satisfied in S. In that case you have to add Eplus to S and you have to remove Eminus from S. The result of these operations is the new (successor) state S’.
The expression C is satisfied in S means, that all elements of C are elements of S too, written as C ⊆ S. The expression add Eplus to S means, that the set Eplus is unified with the set S, written as Eplus ∪ S (or here: Eplus + S). The expression remove Eminus from S means, that the set Eminus is subtracted from the set S, written as S – Eminus.
The concept of apply change rule X to a given state S resulting in S’ is logically a kind of a derivation. Given S,X you will derive by applicating X the new S’. One can write this as S,X ⊢X S’. The ‘meaning’ of the sign ⊢ is explained above.
Because every successor state S’ can become again a given state S onto which change rules X can be applied — written shortly as X(S)=S’, X(S’)=S”, … — the repeated application of change rules X can generate a whole sequence of states, written as SQ(S,X) = <S’, S”, … Sgoal>.
To realize such a derivation in the real world outside of the thinking of the experts one needs a machine, a computer — formally an automaton — which can read S and X documents and can then can compute the derivation leading to S’. An automaton which is doing such a job is often called a simulator [SIM], abbreviated here as ∑. We could then write with more information:
S,X ⊢∑ S’
This will read: Given a setS of many states S and a set X of change rules we can derive by an actor story simulator ∑ a successor state S’.
A Model M=<S,X>
In this context of a set S and a set of change rules X we can speak of a model M which is defined by these two sets.
A Theory T=<M,∑>
Combining a model M with an actor story simulator ∑ enables a theory T which allows a set of derivations based on the model, written as SQ(S,X,⊢∑) = <S’, S”, … Sgoal>. Every derived final state Sgoal in such a derivation is called a theorem of T.
An Empirical Theory Temp
An empirical theory Temp is possible if there exists a theory T with a group of experts which are using this theory and where these experts can interpret the expressions used in theory T by their built-in meaning functions in a way that they always can decide whether the expressions are related to a real situation or not.
Evaluation [ε]
If one generates an Actor Story Theory [TAS] then it can be of practical importance to get some measure how good this theory is. Because measurement is always an operation of comparison between the subject x to be measured and some agreed standard s one has to clarify which kind of a standard for to be good is available. In the general case the only possible source of standards are the experts themselves. In the context of an Actor Story the experts have agreed to some vision [V] which they think to be a better state than a given state S classified as a problem [P]. These assumptions allow a possible evaluation of a given state S in the ‘light’ of an agreed vision V as follows:
ε: V x S —> |V ⊆ S|[%]
ε(V,S) = |V ⊆ S|[%]
This reads as follows: the evaluation ε is a mapping from the sets V and S into the number of elements from the set V included in the set S converted in the percentage of the number of elements included. Thus if no element of V is included in the set S then 0% of the vision is realized, if all elements are included then 100%, etc. As more ‘fine grained’ the set V is as more ‘fine grained’ the evaluation can be.
An Evaluated Theory Tε=<M,∑,ε>
If one combines the concept of a theory T with the concept of evaluation ε then one can use the evaluation in combination with the derivation in the way that every state in a derivation SQ(S,X,⊢∑) = <S’, S”, … Sgoal> will additionally be evaluated, thus one gets sequences of pairs as follows:
In the ideal case Sgoal is evaluated to 100% ‘good’. In real cases 100% is only an ideal value which usually will only be approximated until some threshold.
An Evaluated Theory Tε with Algorithmic Intelligence Tε,α=<M,∑,ε,α>
Because every theory defines a so-called problem space which is here enhanced by some evaluation function one can add an additional operation α (realized by an algorithm) which can repeat the simulator based derivations enhanced with the evaluations to identify those sets of theorems which are qualified as the best theorems according to some criteria given. This operation α is here called algorithmic intelligence of an actor story [αAS]. The existence of such an algorithmic intelligence of an actor story [αAS] allows the introduction of another derivation concept:
S,X ⊢∑,ε,α S* ⊆ S’
This reads as follows: Given a set S and a set X an evaluated theory with algorithmic intelligence Tε,α can derive a subset S* of all possible theorems S’ where S* matches certain given criteria within V.
WHERE WE ARE NOW
As it should have become clear now the work of HMI analysis is the elaboration of a story which can be done in the format of different kinds of theories all of which can be simulated and evaluated. Even better, the only language you have to know is your everyday language, your mother tongue (mathematics is understood here as a sub-language of the everyday language, which in some special cases can be of some help). For this theory every human person — in all ages! — can be a valuable colleague to help you in understanding better possible futures. Because all parts of an actor story theory are plain texts, everybody ran read and understand everything. And if different groups of experts have investigated different aspects of a common field you can merge all texts by only ‘pressing a button’ and you will immediately see how all these texts either work together or show discrepancies. The last effect is a great opportunity to improve learning and understanding! Together we represent some of the power of life in the universe.
Integrating Engineering and the Human Factor (info@uffmm.org)
eJournal uffmm.org ISSN 2567-6458, January 8, 2021
Author: Gerd Doeben-Henisch
Email: gerd@doeben-henisch.de
CONTEXT
As described in the uffmm eJournal the wider context of this software project is an integrated engineering theory called Distributed Actor-Actor Interaction [DAAI]. This includes Human Machine Intelligence [HMIntelligence] as part of Human Machine Interaction [HMI]. In the section Case Studies of the uffmm eJournal there is also a section about Python co-learning – mainly dealing with python programming – and a section about a web-server with Dragon. This document is part of the Case Studies section.
CONTENT
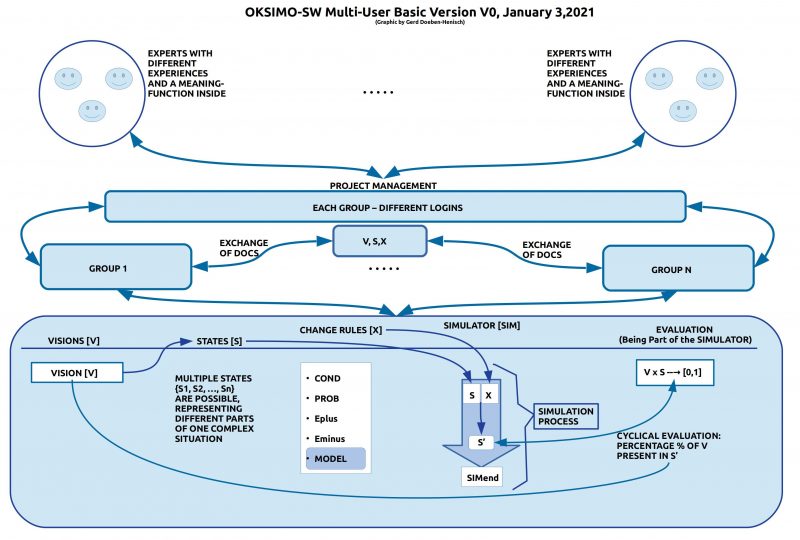
In the long way of making the theory as well as the software [SW] more concrete we have reached January 5, 2021 a first published version on [www.]oksimo.com. This version contains a sub-part of the whole concept which I call here the Minimal Basic Version [MBV] of the osimo SW. This minimal basic will be tested until the end of february 2021. Then we will add stepwise all the other intended features.
THE MINIMAL BASIC VERSION
oksimo SW Minimal Basic Version Jan 3, 2021
If one compares this figure with the figure of the Multi-Group Management from Dec 5, 2020 one can easily detect simplifications for the first modul now called Vision [V] as well as for the last modul called Evaluation [EVAL].
While the basic modules States [S], Change Rules [X] and Simulator [SIM] stayed the same the mentioned first and last module have slightly changed in the sense that they have become simplified.
During the first tests with the oksimo reloaded SW it became clear that for a simulation unified with evaluation it is sufficient to have at least one visionV to be compared with an actual state S whether parts of the vision V are also part of the state S. This induced the requirement that a vision V has to be understood as a collection of statements where earch statement describes some aspect of a vision as a whole.
Example 1: Thus a global vision of a city to have a ‘Kindergarten’ could be extended with facts like ‘It is free for all children’, ‘I is constructed in an ecological acceptable manner’, …
Example 2: A global vision to have a system interface [SI]for the oksimo reloaded SW could include statements (facts) like: ‘The basic mode is text input in an everyday language’, ‘In an advanced mode you can use speech-recognition tools to enter a text into the system’, ‘The basic mode of the simulation output is text-based’, ‘In an advanced mode you can use text-to-speech SW to allow audio-output of the simulation’, ….
Vision V – Statement S: The citizen which will work with the oksimo reloaded SW has now only to distinguish between the vision V which points into some — as such — unknown future and the given situation S describing some part of the everyday world. The vision with all its possible different partial views (statements, facts) can then be used to a evaluate a given state S whether the vision is already part of it or not. If during a simulation a state S* has been reached and the global vision ‘The city has a Kindergarten’ is part of S* but not the partial aspects ‘It is free for all children’, ‘I is constructed in an ecological acceptable manner’, then only one third of the vision has been fulfilled: eval(V,S*)= 33,3 … %. As one can see the amount of vision facts determines the fineness of the evaluation.
Requirements Point of View: In Software Engineering [SWE] and — more general — in Human-Machine Interaction [HMI] as part of System Engineering [SE] the analysis phase is characterized by a list of functional and non-functional requirements [FR, NFR]. Both concepts are in the oksimo SW parts of the vision modul. Everything you think of to be important for your vision you can write down as some aspect of the vision. And if you want to structure your vision into several parts you can edit different vision documents which for a simulation can be united to one document again.
Change Rules [X]: In the minimal basic version only three components of a change rule X will be considered: The condition [COND] part which checks whether an actual state S satisfies (fulfills) the condition; the Eplus part which contains facts which shall be added to the actual state S for the next turn; the Eminus part which contains facts which shall be removed from the actual state S für the next turn. Other components like Probability [PROB] or Model [MODEL] will be added in the future.
Integrating Engineering and the Human Factor (info@uffmm.org) eJournal uffmm.org ISSN 2567-6458, Nov 12, 2020
Author: Gerd Doeben-Henisch
Email: gerd@doeben-henisch.de
The analysis of the main application scenario revealed that classical
logical inference concepts are insufficient for the assistance of human ac-
tors during shared planning. It turned out that the simulator has to be
understood as a real learning artificial actor which has to gain the required
knowledge during the process.
The two papers of Tarski, which I do discuss here, have been published in 1936. Occasionally I have already read these paper many years ago but at that time I could not really work with these papers. Formally they seemed to be ’correct’, but in the light of my ’intuition’ the message appeared to me somehow ’weird’, not really in conformance with my experience of how knowledge and language are working in the real world. But at that time I was not able to explain my intuition to myself sufficiently. Nevertheless, I kept these papers – and some more texts of Tarski – in my bookshelves for an unknown future when my understanding would eventually change…
This happened the last days.