This post is part of the uffmm.org blog and has no direct predecessor, but the subject is thematically related to the larger topic of ’empirical theory’.
CONTENT
This text is devoted to Günter Wagner, who paved the way for many achievements in Research, Technology and Industry, and thereby for Society too. Born in 1934 his life is interwoven with many important events in history and his personal knowledge about these events is striking. The center of his experience and knowledge is mass spectrometry and the more specialized perspective of gas chromatography-mass spectrometry [1,2]. Günter Wagner is dealing with this topic from many sides: theoretical foundations, technological realizations, and different applications in industry, accompanied with many new improvements in the applied technologies.
The author of this text is a ‘layman’ in the field of mass spectrometry. His experience is centered around the topic of Philosophy of science, Cognitive Sciences as well as Computer Science. Besides the many interesting points in the knowledge and work of Günter Wagner the author of this text is focusing on the ‘role’ of mass spectrometry in the ‘measurement’ of real world objects and properties as starting point for possible theories.
With this setting the encounter with Günter Wagner can be understood as an ‘experiment in trans-disciplinary understanding’ of one field — mass spectrometry — from the point of another field — Philosophy of Science. Such an approach is not a simple undertaking. It needed about 30 years of personal knowledge of each other for this idea to take shape. What will be the outcome is at the time of this writing ‘open’.
The ‘Man-in-the-Middle’ (Last Change: 29.December 2022) What measurement means to theory-building by using mass spectroscopy.
…
COMMENTS
wkp := wikipedia
[1] Mass Spectrometry in wkp [EN] : https://en.wikipedia.org/wiki/Mass_spectrometry (Last access: 28.Dec 2022)
[2] Gas chromatography-mass spectrometry in wkp [EN] : https://en.wikipedia.org/wiki/Gas_chromatography%E2%80%93mass_spectrometry (Last access: 28.Dec 2022)
In this review I discuss the ideas of the book The Psychology of Science (1966) from A.Maslow. His book is in a certain sense outstanding because the point of view is in one respect inspired by an artificial borderline between the mainstream-view of empirical science and the mainstream-view of psychotherapy. In another respect the book discusses a possible integrated view of empirical science with psychotherapy as an integral part. The point of view of the reviewer is the new paradigm of a Generative Cultural Anthropology[GCA]. Part II of this review reports some considerations reflecting the relationship of the point of view of Maslow and the point of view of GCA.
In this review I discuss the ideas of the book The Psychology of Science (1966) from A.Maslow. His book is in a certain sense outstanding because the point of view is in one respect inspired by an artificial borderline between the mainstream-view of empirical science and the mainstream-view of psychotherapy. In another respect the book discusses a possible integrated view of empirical science with psychotherapy as an integral part. The point of view of the reviewer is the new paradigm of a Generative Cultural Anthropology[GCA]. Part I of this review gives a summary of the content of the book as understood by the reviewer and part II reports some considerations reflecting the relationship of the point of view of Maslow and the point of view of GCA.
Last change: 23.February 2019 (continued the text)
Last change: 24.February 2019 (extended the text)
CONTEXT
In the overview of the AAI paradigm version 2 you can find this section dealing with the philosophical perspective of the AAI paradigm. Enjoy reading (or not, then send a comment :-)).
THE DAILY LIFE PERSPECTIVE
The perspective of Philosophy is rooted in the everyday life perspective. With our body we occur in a space with other bodies and objects; different features, properties are associated with the objects, different kinds of relations an changes from one state to another.
From the empirical sciences we have learned to see more details of the everyday life with regard to detailed structures of matter and biological life, with regard to the long history of the actual world, with regard to many interesting dynamics within the objects, within biological systems, as part of earth, the solar system and much more.
A certain aspect of the empirical view of the world is the fact, that some biological systems called ‘homo sapiens’, which emerged only some 300.000 years ago in Africa, show a special property usually called ‘consciousness’ combined with the ability to ‘communicate by symbolic languages’.
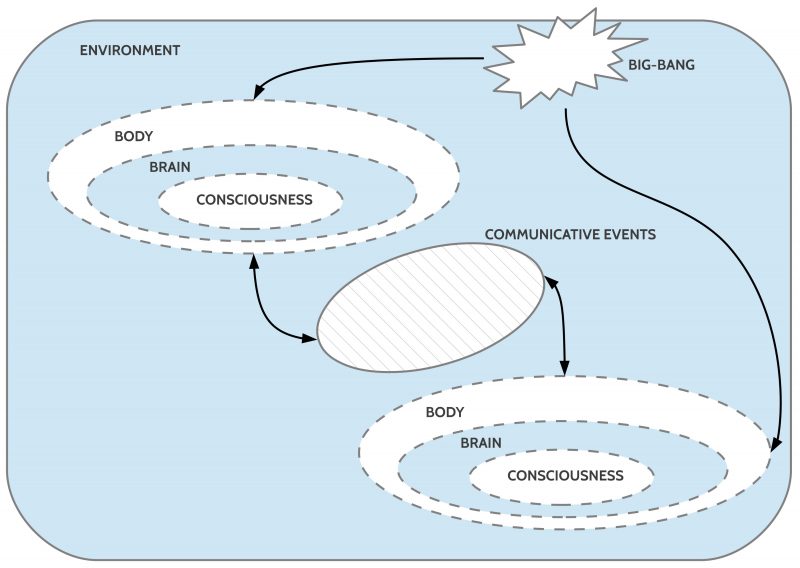
Figure 1: General setting of the homo sapiens species (simplified)
As we know today the consciousness is associated with the brain, which in turn is embedded in the body, which is further embedded in an environment.
Thus those ‘things’ about which we are ‘conscious’ are not ‘directly’ the objects and events of the surrounding real world but the ‘constructions of the brain’ based on actual external and internal sensor inputs as well as already collected ‘knowledge’. To qualify the ‘conscious things’ as ‘different’ from the assumed ‘real things’ ‘outside there’ it is common to speak of these brain-generated virtual things either as ‘qualia’ or — more often — as ‘phenomena’ which are different to the assumed possible real things somewhere ‘out there’.
PHILOSOPHY AS FIRST PERSON VIEW
‘Philosophy’ has many facets. One enters the scene if we are taking the insight into the general virtual character of our primary knowledge to be the primary and irreducible perspective of knowledge. Every other more special kind of knowledge is necessarily a subspace of this primary phenomenological knowledge.
There is already from the beginning a fundamental distinction possible in the realm of conscious phenomena (PH): there are phenomena which can be ‘generated’ by the consciousness ‘itself’ — mostly called ‘by will’ — and those which are occurring and disappearing without a direct influence of the consciousness, which are in a certain basic sense ‘given’ and ‘independent’, which are appearing and disappearing according to ‘their own’. It is common to call these independent phenomena ’empirical phenomena’ which represent a true subset of all phenomena: PH_emp ⊂ PH. Attention: These empirical phenomena’ are still ‘phenomena’, virtual entities generated by the brain inside the brain, not directly controllable ‘by will’.
There is a further basic distinction which differentiates the empirical phenomena into those PH_emp_bdy which are controlled by some processes in the body (being tired, being hungry, having pain, …) and those PH_emp_ext which are controlled by objects and events in the environment beyond the body (light, sounds, temperature, surfaces of objects, …). Both subsets of empirical phenomena are different: PH_emp_bdy ∩ PH_emp_ext = 0. Because phenomena usually are occurring associated with typical other phenomena there are ‘clusters’/ ‘pattern’ of phenomena which ‘represent’ possible events or states.
Modern empirical science has ‘refined’ the concept of an empirical phenomenon by introducing ‘standard objects’ which can be used to ‘compare’ some empirical phenomenon with such an empirical standard object. Thus even when the perception of two different observers possibly differs somehow with regard to a certain empirical phenomenon, the additional comparison with an ’empirical standard object’ which is the ‘same’ for both observers, enhances the quality, improves the precision of the perception of the empirical phenomena.
From these considerations we can derive the following informal definitions:
Something is ‘empirical‘ if it is the ‘real counterpart’ of a phenomenon which can be observed by other persons in my environment too.
Something is ‘standardized empirical‘ if it is empirical and can additionally be associated with a before introduced empirical standard object.
Something is ‘weak empirical‘ if it is the ‘real counterpart’ of a phenomenon which can potentially be observed by other persons in my body as causally correlated with the phenomenon.
Something is ‘cognitive‘ if it is the counterpart of a phenomenon which is not empirical in one of the meanings (1) – (3).
It is a common task within philosophy to analyze the space of the phenomena with regard to its structure as well as to its dynamics. Until today there exists not yet a complete accepted theory for this subject. This indicates that this seems to be some ‘hard’ task to do.
BRIDGING THE GAP BETWEEN BRAINS
As one can see in figure 1 a brain in a body is completely disconnected from the brain in another body. There is a real, deep ‘gap’ which has to be overcome if the two brains want to ‘coordinate’ their ‘planned actions’.
Luckily the emergence of homo sapiens with the new extended property of ‘consciousness’ was accompanied by another exciting property, the ability to ‘talk’. This ability enabled the creation of symbolic languages which can help two disconnected brains to have some exchange.
But ‘language’ does not consist of sounds or a ‘sequence of sounds’ only; the special power of a language is the further property that sequences of sounds can be associated with ‘something else’ which serves as the ‘meaning’ of these sounds. Thus we can use sounds to ‘talk about’ other things like objects, events, properties etc.
The single brain ‘knows’ about the relationship between some sounds and ‘something else’ because the brain is able to ‘generate relations’ between brain-structures for sounds and brain-structures for something else. These relations are some real connections in the brain. Therefore sounds can be related to ‘something else’ or certain objects, and events, objects etc. can become related to certain sounds. But these ‘meaning relations’ can only ‘bridge the gap’ to another brain if both brains are using the same ‘mapping’, the same ‘encoding’. This is only possible if the two brains with their bodies share a real world situation RW_S where the perceptions of the both brains are associated with the same parts of the real world between both bodies. If this is the case the perceptions P(RW_S) can become somehow ‘synchronized’ by the shared part of the real world which in turn is transformed in the brain structures P(RW_S) —> B_S which represent in the brain the stimulating aspects of the real world. These brain structures B_S can then be associated with some sound structures B_A written as a relation MEANING(B_S, B_A). Such a relation realizes an encoding which can be used for communication. Communication is using sound sequences exchanged between brains via the body and the air of an environment as ‘expressions’ which can be recognized as part of a learned encoding which enables the receiving brain to identify a possible meaning candidate.
DIFFERENT MODES TO EXPRESS MEANING
Following the evolution of communication one can distinguish four important modes of expressing meaning, which will be used in this AAI paradigm.
VISUAL ENCODING
A direct way to express the internal meaning structures of a brain is to use a ‘visual code’ which represents by some kinds of drawing the visual shapes of objects in the space, some attributes of shapes, which are common for all people who can ‘see’. Thus a picture and then a sequence of pictures like a comic or a story board can communicate simple ideas of situations, participating objects, persons and animals, showing changes in the arrangement of the shapes in the space.
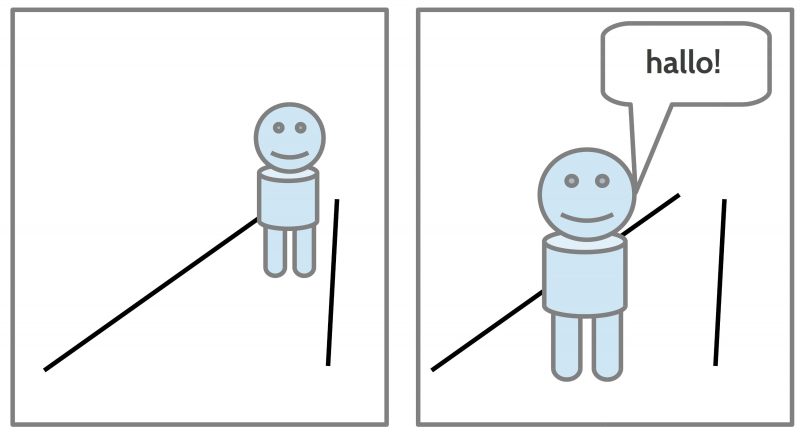
Figure 2: Pictorial expressions representing aspects of the visual and the auditory sens modes
Even with a simple visual code one can generate many sequences of situations which all together can ‘tell a story’. The basic elements are a presupposed ‘space’ with possible ‘objects’ in this space with different positions, sizes, relations and properties. One can even enhance these visual shapes with written expressions of a spoken language. The sequence of the pictures represents additionally some ‘timely order’. ‘Changes’ can be encoded by ‘differences’ between consecutive pictures.
FROM SPOKEN TO WRITTEN LANGUAGE EXPRESSIONS
Later in the evolution of language, much later, the homo sapiens has learned to translate the spoken language L_s in a written format L_w using signs for parts of words or even whole words. The possible meaning of these written expressions were no longer directly ‘visible’. The meaning was now only available for those people who had learned how these written expressions are associated with intended meanings encoded in the head of all language participants. Thus only hearing or reading a language expression would tell the reader either ‘nothing’ or some ‘possible meanings’ or a ‘definite meaning’.
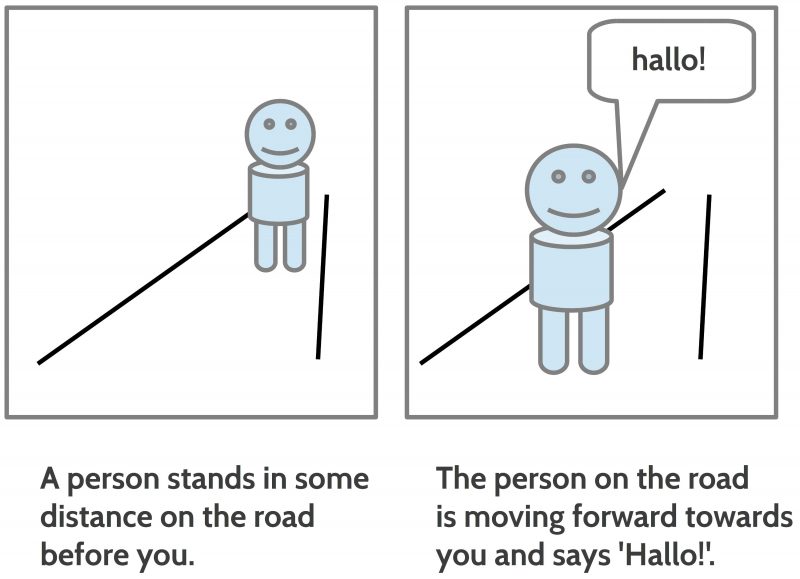
Figure 3: A written textual version in parallel to a pictorial version
If one has only the written expressions then one has to ‘know’ with which ‘meaning in the brain’ the expressions have to be associated. And what is very special with the written expressions compared to the pictorial expressions is the fact that the elements of the pictorial expressions are always very ‘concrete’ visual objects while the written expressions are ‘general’ expressions allowing many different concrete interpretations. Thus the expression ‘person’ can be used to be associated with many thousands different concrete objects; the same holds for the expression ‘road’, ‘moving’, ‘before’ and so on. Thus the written expressions are like ‘manufacturing instructions’ to search for possible meanings and configure these meanings to a ‘reasonable’ complex matter. And because written expressions are in general rather ‘abstract’/ ‘general’ which allow numerous possible concrete realizations they are very ‘economic’ because they use minimal expressions to built many complex meanings. Nevertheless the daily experience with spoken and written expressions shows that they are continuously candidates for false interpretations.
FORMAL MATHEMATICAL WRITTEN EXPRESSIONS
Besides the written expressions of everyday languages one can observe later in the history of written languages the steady development of a specialized version called ‘formal languages’ L_f with many different domains of application. Here I am focusing on the formal written languages which are used in mathematics as well as some pictorial elements to ‘visualize’ the intended ‘meaning’ of these formal mathematical expressions.
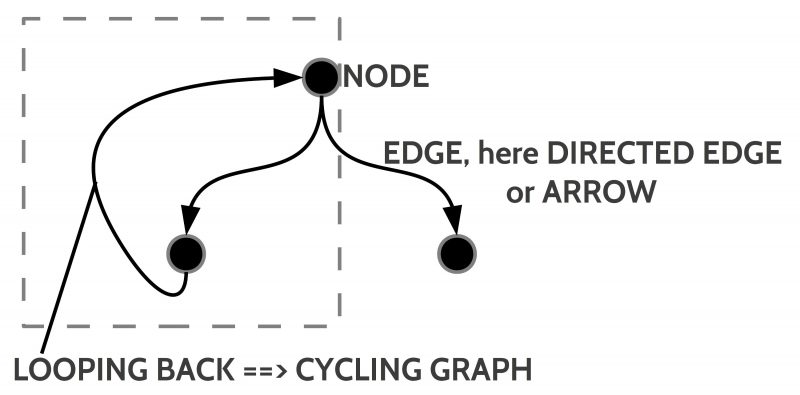
Fig. 4: Properties of an acyclic directed graph with nodes (vertices) and edges (directed edges = arrows)
One prominent concept in mathematics is the concept of a ‘graph’. In the basic version there are only some ‘nodes’ (also called vertices) and some ‘edges’ connecting the nodes. Formally one can represent these edges as ‘pairs of nodes’. If N represents the set of nodes then N x N represents the set of all pairs of these nodes.
In a more specialized version the edges are ‘directed’ (like a ‘one way road’) and also can be ‘looped back’ to a node occurring ‘earlier’ in the graph. If such back-looping arrows occur a graph is called a ‘cyclic graph’.
Fig.5: Directed cyclic graph extended to represent ‘states of affairs’
If one wants to use such a graph to describe some ‘states of affairs’ with their possible ‘changes’ one can ‘interpret’ a ‘node’ as a state of affairs and an arrow as a change which turns one state of affairs S in a new one S’ which is minimally different to the old one.
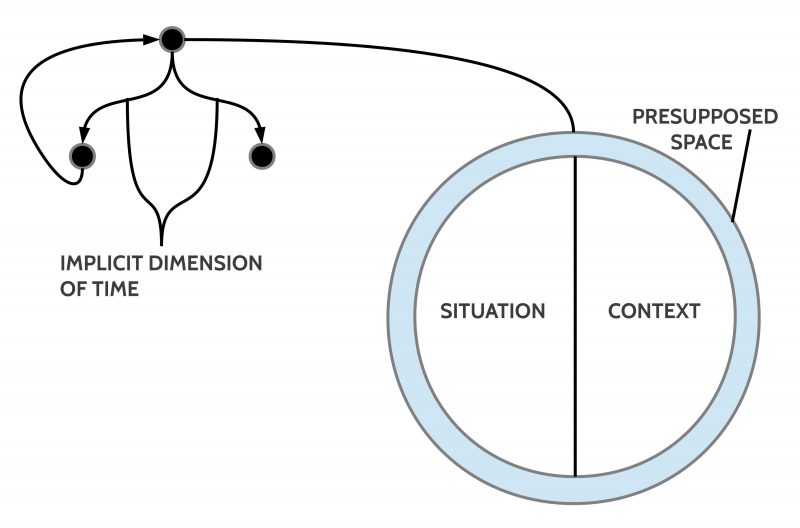
As a state of affairs I understand here a ‘situation’ embedded in some ‘context’ presupposing some common ‘space’. The possible ‘changes’ represented by arrows presuppose some dimension of ‘time’. Thus if a node n’ is following a node n indicated by an arrow then the state of affairs represented by the node n’ is to interpret as following the state of affairs represented in the node n with regard to the presupposed time T ‘later’, or n < n’ with ‘<‘ as a symbol for a timely ordering relation.
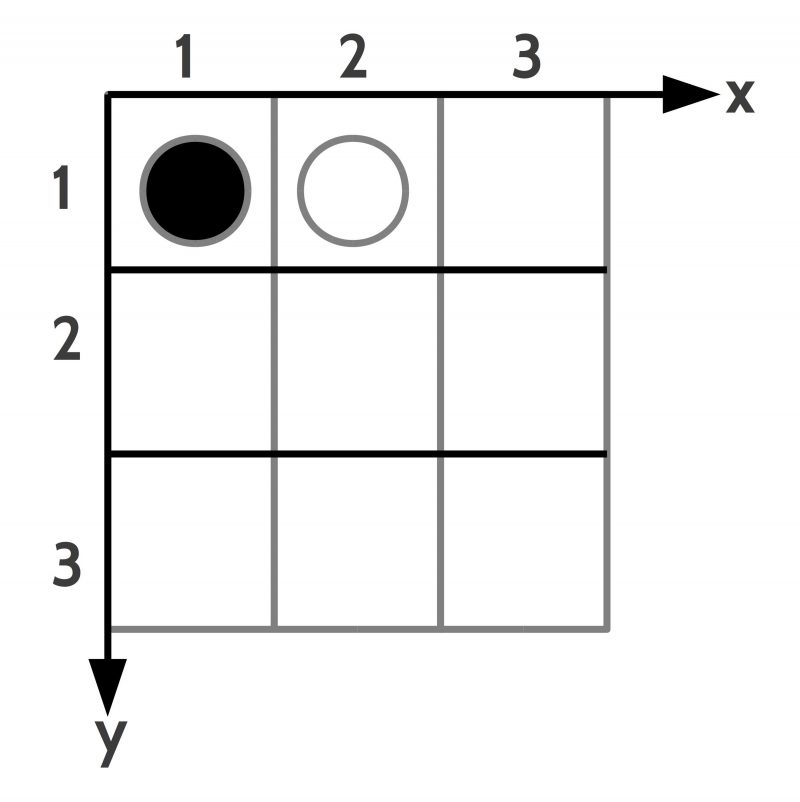
Fig.6: Example of a state of affairs with a 2-dimensional space configured as a grid with a black and a white token
The space can be any kind of a space. If one assumes as an example a 2-dimensional space configured as a grid –as shown in figure 6 — with two tokens at certain positions one can introduce a language to describe the ‘facts’ which constitute the state of affairs. In this example one needs ‘names for objects’, ‘properties of objects’ as well as ‘relations between objects’. A possible finite set of facts for situation 1 could be the following:
TOKEN(T1), BLACK(T1), POSITION(T1,1,1)
TOKEN(T2), WHITE(T2), POSITION(T2,2,1)
NEIGHBOR(T1,T2)
CELL(C1), POSITION(1,2), FREE(C1)
‘T1’, ‘T2’, as well as ‘C1’ are names of objects, ‘TOKEN’, ‘BACK’ etc. are names of properties, and ‘NEIGHBOR’ is a relation between objects. This results in the equation:
These facts describe the situation S1. If it is important to describe possible objects ‘external to the situation’ as important factors which can cause some changes then one can describe these objects as a set of facts in a separated ‘context’. In this example this could be two players which can move the black and white tokens and thereby causing a change of the situation. What is the situation and what belongs to a context is somewhat arbitrary. If one describes the agriculture of some region one usually would not count the planets and the atmosphere as part of this region but one knows that e.g. the sun can severely influence the situation in combination with the atmosphere.
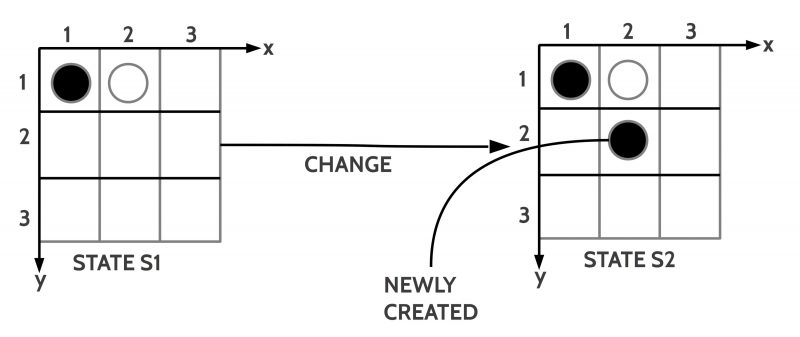
Fig.7: Change of a state of affairs given as a state which will be enhanced by a new object
Let us stay with a state of affairs with only a situation without a context. The state of affairs is a ‘state’. In the example shown in figure 6 I assume a ‘change’ caused by the insertion of a new black token at position (2,2). Written in the language of facts L_fact we get:
Thus the new state S2 is generated out of the old state S1 by unifying S1 with the set of new facts: S2 = S1 ∪ {TOKEN(T3), BLACK(T3), POSITION(2,2), NEIGHBOR(T3,T2)}. All the other facts of S1 are still ‘valid’. In a more general manner one can introduce a change-expression with the following format:
This can be read as follows: The follow-up state S2 is generated out of the state S1 by adding to the state S1 the set of facts { … }.
This layout of a change expression can also be used if some facts have to be modified or removed from a state. If for instance by some reason the white token should be removed from the situation one could write:
These simple examples demonstrate another fact: while facts about objects and their properties are independent from each other do relational facts depend from the state of their object facts. The relation of neighborhood e.g. depends from the participating neighbors. If — as in the example above — the object token T2 disappears then the relation ‘NEIGHBOR(T1,T2)’ no longer holds. This points to a hierarchy of dependencies with the ‘basic facts’ at the ‘root’ of a situation and all the other facts ‘above’ basic facts or ‘higher’ depending from the basic facts. Thus ‘higher order’ facts should be added only for the actual state and have to be ‘re-computed’ for every follow-up state anew.
If one would specify a context for state S1 saying that there are two players and one allows for each player actions like ‘move’, ‘insert’ or ‘delete’ then one could make the change from state S1 to state S2 more precise. Assuming the following facts for the context:
PLAYER(PB1), PLAYER(PW1), HAS-THE-TURN(PB1)
In that case one could enhance the change statement in the following way:
This would read as follows: given state S1 the player PB1 inserts a black token at position (2,2); this yields a new state S2.
With or without a specified context but with regard to a set of possible change statements it can be — which is the usual case — that there is more than one option what can be changed. Some of the main types of changes are the following ones:
RANDOM
NOT RANDOM, which can be specified as follows:
With PROBABILITIES (classical, quantum probability, …)
DETERMINISTIC
Furthermore, if the causing object is an actor which can adapt structurally or even learn locally then this actor can appear in some time period like a deterministic system, in different collected time periods as an ‘oscillating system’ with different behavior, or even as a random system with changing probabilities. This make the forecast of systems with adaptive and/ or learning systems rather difficult.
Another aspect results from the fact that there can be states either with one actor which can cause more than one action in parallel or a state with multiple actors which can act simultaneously. In both cases the resulting total change has eventually to be ‘filtered’ through some additional rules telling what is ‘possible’ in a state and what not. Thus if in the example of figure 6 both player want to insert a token at position (2,2) simultaneously then either the rules of the game would forbid such a simultaneous action or — like in a computer game — simultaneous actions are allowed but the ‘geometry of a 2-dimensional space’ would not allow that two different tokens are at the same position.
Another aspect of change is the dimension of time. If the time dimension is not explicitly specified then a change from some state S_i to a state S_j does only mark the follow up state S_j as later. There is no specific ‘metric’ of time. If instead a certain ‘clock’ is specified then all changes have to be aligned with this ‘overall clock’. Then one can specify at what ‘point of time t’ the change will begin and at what point of time t*’ the change will be ended. If there is more than one change specified then these different changes can have different timings.
THIRD PERSON VIEW
Up until now the point of view describing a state and the possible changes of states is done in the so-called 3rd-person view: what can a person perceive if it is part of a situation and is looking into the situation. It is explicitly assumed that such a person can perceive only the ‘surface’ of objects, including all kinds of actors. Thus if a driver of a car stears his car in a certain direction than the ‘observing person’ can see what happens, but can not ‘look into’ the driver ‘why’ he is steering in this way or ‘what he is planning next’.
A 3rd-person view is assumed to be the ‘normal mode of observation’ and it is the normal mode of empirical science.
Nevertheless there are situations where one wants to ‘understand’ a bit more ‘what is going on in a system’. Thus a biologist can be interested to understand what mechanisms ‘inside a plant’ are responsible for the growth of a plant or for some kinds of plant-disfunctions. There are similar cases for to understand the behavior of animals and men. For instance it is an interesting question what kinds of ‘processes’ are in an animal available to ‘navigate’ in the environment across distances. Even if the biologist can look ‘into the body’, even ‘into the brain’, the cells as such do not tell a sufficient story. One has to understand the ‘functions’ which are enabled by the billions of cells, these functions are complex relations associated with certain ‘structures’ and certain ‘signals’. For this it is necessary to construct an explicit formal (mathematical) model/ theory representing all the necessary signals and relations which can be used to ‘explain’ the obsrvable behavior and which ‘explains’ the behavior of the billions of cells enabling such a behavior.
In a simpler, ‘relaxed’ kind of modeling one would not take into account the properties and behavior of the ‘real cells’ but one would limit the scope to build a formal model which suffices to explain the oservable behavior.
This kind of approach to set up models of possible ‘internal’ (as such hidden) processes of an actor can extend the 3rd-person view substantially. These models are called in this text ‘actor models (AM)’.
HIDDEN WORLD PROCESSES
In this text all reported 3rd-person observations are called ‘actor story’, independent whether they are done in a pictorial or a textual mode.
As has been pointed out such actor stories are somewhat ‘limited’ in what they can describe.
It is possible to extend such an actor story (AS) by several actor models (AM).
An actor story defines the situations in which an actor can occur. This includes all kinds of stimuli which can trigger the possible senses of the actor as well as all kinds of actions an actor can apply to a situation.
The actor model of such an actor has to enable the actor to handle all these assumed stimuli as well as all these actions in the expected way.
While the actor story can be checked whether it is describing a process in an empirical ‘sound’ way, the actor models are either ‘purely theoretical’ but ‘behavioral sound’ or they are also empirically sound with regard to the body of a biological or a technological system.
A serious challenge is the occurrence of adaptiv or/ and locally learning systems. While the actor story is a finite description of possible states and changes, adaptiv or/ and locally learning systeme can change their behavior while ‘living’ in the actor story. These changes in the behavior can not completely be ‘foreseen’!
COGNITIVE EXPERT PROCESSES
According to the preceding considerations a homo sapiens as a biological system has besides many properties at least a consciousness and the ability to talk and by this to communicate with symbolic languages.
Looking to basic modes of an actor story (AS) one can infer some basic concepts inherently present in the communication.
Without having an explicit model of the internal processes in a homo sapiens system one can infer some basic properties from the communicative acts:
Speaker and hearer presuppose a space within which objects with properties can occur.
Changes can happen which presuppose some timely ordering.
There is a disctinction between concrete things and abstract concepts which correspond to many concrete things.
There is an implicit hierarchy of concepts starting with concrete objects at the ‘root level’ given as occurence in a concrete situation. Other concepts of ‘higher levels’ refer to concepts of lower levels.
There are different kinds of relations between objects on different conceptual levels.
The usage of language expressions presupposes structures which can be associated with the expressions as their ‘meanings’. The mapping between expressions and their meaning has to be learned by each actor separately, but in cooperation with all the other actors, with which the actor wants to share his meanings.
It is assume that all the processes which enable the generation of concepts, concept hierarchies, relations, meaning relations etc. are unconscious! In the consciousness one can use parts of the unconscious structures and processes under strictly limited conditions.
To ‘learn’ dedicated matters and to be ‘critical’ about the quality of what one is learnig requires some disciplin, some learning methods, and a ‘learning-friendly’ environment. There is no guaranteed method of success.
There are lots of unconscious processes which can influence understanding, learning, planning, decisions etc. and which until today are not yet sufficiently cleared up.
An overview to the enhanced AAI theory version 2 you can find here. In this post we talk about the special topic how the actor story (AS) can be used for a modeling of the real world (RW).
AS AND REAL WORLD MODELING
In the preceding post you find a rough description how an actor story can be generated challenged by a problem P. Here I shall address the question, how this procedure can be used to model certain aspects of the real world and not some abstract ideas only.
There are two main elements of the actor story which can be related to the real world: (i) The start state of the actor story and the list of possible change expressions.
FACTS
A start state is a finite set of facts which in turn are — in the case of the mathematical language — constituted by names of objects associated with properties or relations. Primarily the possible meaning of these expressions is located in the cognitive structures of the actors. These cognitive structures are as such not empirical entities and are partially available in a state called consciousness. If some element of meaning is conscious andsimultaneously part of the inter-subjective space between different actors in a way that all participating actors can perceive these elements, then these elements are called empirical by everyday experience, if these facts can be decided between the participants of the situation. If there exist further explicit measurement procedures associating an inter-subjective property with inter-subjective measurement data then these elements are called genuineempirical data.
Thus the collection of facts constituting a state of an actor story can be realized as a set of empirical facts, at least in the format of empirical by everyday experience.
CHANGES
While a state represents only static facts, one needs an additional element to be able to model the dynamic aspect of the real world. This is realized by change expressions X.
The general idea of a change is that at least one fact f of an actual state (= NOW), is changed either by complete disappearance or by changing some of its properties or by the creation of a new fact f1. An object called ‘B1’ with the property being ‘red’ — written as ‘RED(B1)’ — perhaps changes its property from being ‘red’ to become ‘blue’ — written as ‘BLUE(B1)’ –. Then the set of facts of the actual state S0= {RED(B1)} will change to a successor state S1={BLUE(B1)}. In this case the old fact ‘RED(B1)’ has been deleted and the new fact ‘BLUE(B1)’ has been created. Another example: the object ‘B1’ has also a ‘weight’ measured in kg which changes too. Then the actual state was S0={RED(B1), WEIGHT(B1,kg,2.4)} and this state changed to the successor state S1= {BLUE(B1), WEIGHT(B1,kg,3.4)}.
The possible cause of a change can be either an object or the ‘whole state‘ representing the world.
The mapping from a given state s into a successor state s’ by subtracting facts f- and joining facts f+ is here called an action: S –> S-(f-) u (f+) or action(s) = s’ = s-(f-) u (f+) with s , s’ in S
Because an action has an actor as a carrier one can write action: S x A –> S-(f-) u (f+) or action_a(s) = s’.
The defining properties of such an action are given in the sets of facts to be deleted — written as ‘d:{f-}’ — and the sets of facts to be created — written ‘c:{f+}’ –.
A full change expression amounts then to the following format: <s,s’, obj-name, action-name, d:{…}, c:{…}>.
But this is not yet the whole story. A change can be deterministic or indeterministic.
The deterministic change is cause by a deterministic actor or by a deterministic world.
The indeterministic change can have several formats:e.g. classical probability or quantum-like probability or the an actor as cause, whose behavior is not completely deterministic.
Additionally there can be interactions between different objects which can cause a change and these changes happen in parallel, simultaneously. Depending from the assumed environment (= world) and some laws describing the behavior of this world it can happen, that different local actions can hinder each other or change the effect of the changes.
Independent of the different kinds of changes it can be required that all used change-expressions should be of that kind that one can state that they are empirical by everyday experience.
TIME
And there is even more to tell. A change has in everyday life a duration measured with certain time units generated by a technical device called a clock.
To improve the empirical precision of change expressions one has to add the duration of the change between the actual state s and the final state s’ showing all the deletes (f-) and creates (f+) which are caused by this change-expression. This can only be done if a standard clock is included in the facts represented by the actual time stamp of this clock. Thus with regard to such a standard time one can realize a change with duration (t,t’) exactly in coherence with the standard time. A special case is given when a change-expression describes the effects of its actions in a distributed manner by giving more than one time point (t,t1, …, tn) and associating different deletes and creates with different points of time. Those distributed effects can make an actor story rather complex and difficult to understand by human brains.
An overview to the enhanced AAI theory version 2 you can find here. In this post we talk about the fourth chapter dealing with the epistemology of actors within an AAI analysis process.
EPISTEMOLOGY AND THE EMPIRICAL SCIENCES
Epistemology is a sub-discipline of general philosophy. While a special discipline in empirical science is defined by a certain sub-set of the real world RW by empirical measurement methods generating empirical data which can be interpreted by a formalized theory, philosophy is not restricted to a sub-field of the real world. This is important because an empirical discipline has no methods to define itself. Chemistry e.g. can define by which kinds of measurement it is gaining empirical data and it can offer different kinds of formal theories to interpret these data including inferences to forecast certain reactions given certain configurations of matters, but chemistry is not able to explain the way how a chemist is thinking, how the language works which a chemist is using etc. Thus empirical science presupposes a general framework of bodies, sensors, brains, languages etc. to be able to do a very specialized — but as such highly important — job. One can define ‘philosophy’ then as that kind of activity which tries to clarify all these conditions which are necessary to do science as well as how cognition works in the general case.
Given this one can imagine that philosophy is in principle a nearly ‘infinite’ task. To get not lost in this conceptual infinity it is recommended to start with concrete processes of communications which are oriented to generate those kinds of texts which can be shown as ‘related to parts of the empirical world’ in a decidable way. This kind of texts is here called ’empirically sound’ or ’empirically true’. It is to suppose that there will be texts for which it seems to be clear that they are empirically sound, others will appear ‘fuzzy’ for such a criterion, others even will appear without any direct relation to empirical soundness.
In empirical sciences one is using so-called empirical measurement procedures as benchmarks to decided whether one has empirical data or not, and it is commonly assumed that every ‘normal observer’ can use these data as every other ‘normal observer’. But because individual, single data have nearly no meaning on their own one needs relations, sets of relations (models) and even more complete theories, to integrate the data in a context, which allows some interpretation and some inferences for forecasting. But these relations, models, or theories can not directly be inferred from the real world. They have to be created by the observers as ‘working hypotheses’ which can fit with the data or not. And these constructions are grounded in highly complex cognitive processes which follow their own built-in rules and which are mostly not conscious. ‘Cognitive processes’ in biological systems, especially in human person, are completely generated by a brain and constitute therefore a ‘virtual world’ on their own. This cognitive virtual world is not the result of a 1-to-1 mapping from the real world into the brain states. This becomes important in that moment where the brain is mapping this virtual cognitive world into some symbolic language L. While the symbols of a language (sounds or written signs or …) as such have no meaning the brain enables a ‘coding’, a ‘mapping’ from symbolic expressions into different states of the brain. In the light’ of such encodings the symbolic expressions have some meaning. Besides the fact that different observers can have different encodings it is always an open question whether the encoded meaning of the virtual cognitive space has something to do with some part of the empirical reality. Empirical data generated by empirical measurement procedures can help to coordinate the virtual cognitive states of different observers with each other, but this coordination is not an automatic process. Empirically sound language expressions are difficult to get and therefore of a high value for the survival of mankind. To generate empirically sound formal theories is even more demanding and until today there exists no commonly accepted concept of the right format of an empirically sound theory. In an era which calls itself ‘scientific’ this is a very strange fact.
EPISTEMOLOGY OF THE AAI-EXPERTS
Applying these general considerations to the AAI experts trying to construct an actor story to describe at least one possible path from a start state to a goal state, one can pick up the different languages the AAI experts are using and asking back under which conditions these languages have some ‘meaning’ and under which conditions these meanings can be called ’empirically sound’?
In this book three different ‘modes’ of an actor story will be distinguished:
A textual mode using some ordinary everyday language, thus using spoken language (stored in an audio file) or written language as a text.
A pictorial mode using a ‘language of pictures’, possibly enhanced by fragments of texts.
A mathematical mode using graphical presentations of ‘graphs’ enhanced by symbolic expressions (text) and symbolic expressions only.
For every mode it has to be shown how an AAI expert can generate an actor story out of the virtual cognitive world of his brain and how it is possible to decided the empirical soundness of the actor story.
This is a continuation from the post about QL Basics Concepts Part 1. The general topic here is the analysis of properties of human behavior, actually narrowed down to the statistical properties. From the different possible theories applicable to statistical properties of behavior here the one called CPT (classical probability theory) is selected for a short examination.
SUMMARY
An analysis of the classical probability theory shows that the empirical application of this theory is limited to static sets of events and probabilities. In the case of biological systems which are adaptive with regard to structure and cognition this does not work. This yields the question whether a quantum probability theory approach does work or not.
THE CPT IDEA
Before we are looking to the case of quantum probability theory (QLPT) let us examine the case of a classical probability theory (CPT) a little bit more.
Generally one has to distinguish the symbolic formal representation of a theory T and some domain of application D distinct from the symbolic representation.
In principle the domain of application D can be nearly anything, very often again another symbolic representation. But in the case of empirical applications we assume usually some subset of ’empirical events’ E of the ’empirical (real) world’ W.
For the following let us assume (for a while) that this is the case, that D is a subset of the empirical world W.
Talking about ‘events in an empirical real world’ presupposes that there there exists a ‘procedure of measurement‘ using a ‘previously defined standard object‘ and a ‘symbolic representation of the measurement results‘.
Furthermore one has to assume a community of ‘observers‘ which have minimal capabilities to ‘observe’, which implies ‘distinctions between different results’, some ‘ordering of successions (before – after)’, to ‘attach symbols according to some rules’ to measurement results, to ‘translate measurement results’ into more abstract concepts and relations.
Thus to speak about empirical results assumes a set of symbolic representations of those events as a finite set of symbolic representations which represent a ‘state in the real world’ which can have a ‘predecessor state before’ and – possibly — a ‘successor state after’ the ‘actual’ state. The ‘quality’ of these measurement representations depends from the quality of the measurement procedure as well as from the quality of the cognitive capabilities of the participating observers.
In the classical probability theory T_cpt as described by Kolmogorov (1932) it is assumed that there is a set E of ‘elementary events’. The set E is assumed to be ‘complete’ with regard to all possible events. The probability P is coming into play with a mapping from E into the set of positive real numbers R+ written as P: E —> R+ or P(E) = 1 with the assumption that all the individual elements e_i of E have an individual probability P(e_i) which obey the rule P(e_1) + P(e_2) + … + P(e_n) = 1.
In the formal theory T_cpt it is not explained ‘how’ the probabilities are realized in the concrete case. In the ‘real world’ we have to identify some ‘generators of events’ G, otherwise we do not know whether an event e belongs to a ‘set of probability events’.
Kolmogorov (1932) speaks about a necessary generator as a ‘set of conditions’ which ‘allows of any number of repetitions’, and ‘a set of events can take place as a result of the establishment of the condition’. (cf. p.3) And he mentions explicitly the case that different variants of the a priori assumed possible events can take place as a set A. And then he speaks of this set A also of an event which has taken place! (cf. p.4)
If one looks to the case of the ‘set A’ then one has to clarify that this ‘set A’ is not an ordinary set of set theory, because in a set every member occurs only once. Instead ‘A’ represents a ‘sequence of events out of the basic set E’. A sequence is in set theory an ‘ordered set’, where some set (e.g. E) is mapped into an initial segment of the natural numbers Nat and in this case the set A contains ‘pairs from E x Nat|\n’ with a restriction of the set Nat to some n. The ‘range’ of the set A has then ‘distinguished elements’ whereby the ‘domain’ can have ‘same elements’. Kolmogorov addresses this problem with the remark, that the set A can be ‘defined in any way’. (cf. p.4) Thus to assume the set A as a set of pairs from the Cartesian product E x Nat|\n with the natural numbers taken from the initial segment of the natural numbers is compatible with the remark of Kolmogorov and the empirical situation.
For a possible observer it follows that he must be able to distinguish different states <s1, s2, …, sm> following each other in the real world, and in every state there is an event e_i from the set of a priori possible events E. The observer can ‘count’ the occurrences of a certain event e_i and thus will get after n repetitions for every event e_i a number of occurrences m_i with m_i/n giving the measured empirical probability of the event e_i.
Example 1: Tossing a coin with ‘head (H)’ or ‘tail (T)’ we have theoretically the probabilities ‘1/2’ for each event. A possible outcome could be (with ‘H’ := 0, ‘T’ := 1): <((0,1), (0,2), (0,3), (1,4), (0,5)> . Thus we have m_H = 4, m_T = 1, giving us m_H/n = 4/5 and m_T/n = 1/5. The sum yields m_H/n + m_T/n = 1, but as one can see the individual empirical probabilities are not in accordance with the theory requiring 1/2 for each. Kolmogorov remarks in his text that if the number of repetitions n is large enough then will the values of the empirically measured probability approach the theoretically defined values. In a simple experiment with a random number generator simulating the tossing of the coin I got the numbers m_Head = 4978, m_Tail = 5022, which gives the empirical probabilities m_Head/1000 = 0.4977 and m_Teil/ 1000 = 0.5021.
This example demonstrates while the theoretical term ‘probability’ is a simple number, the empirical counterpart of the theoretical term is either a simple occurrence of a certain event without any meaning as such or an empirically observed sequence of events which can reveal by counting and division a property which can be used as empirical probability of this event generated by a ‘set of conditions’ which allow the observed number of repetitions. Thus we have (i) a ‘generator‘ enabling the events out of E, we have (ii) a ‘measurement‘ giving us a measurement result as part of an observation, (iii) the symbolic encoding of the measurement result, (iv) the ‘counting‘ of the symbolic encoding as ‘occurrence‘ and (v) the counting of the overall repetitions, and (vi) a ‘mathematical division operation‘ to get the empirical probability.
Example 1 demonstrates the case of having one generator (‘tossing a coin’). We know from other examples where people using two or more coins ‘at the same time’! In this case the set of a priori possible events E is occurring ‘n-times in parallel’: E x … x E = E^n. While for every coin only one of the many possible basic events can occur in one state, there can be n-many such events in parallel, giving an assembly of n-many events each out of E. If we keeping the values of E = {‘H’, ‘T’} then we have four different basic configurations each with probability 1/4. If we define more ‘abstract’ events like ‘both the same’ (like ‘0,0’, ‘1,1’) or ‘both different’ (like ‘0,1’. ‘1,0’), then we have new types of complex events with different probabilities, each 1/2. Thus the case of n-many generators in parallel allows new types of complex events.
Following this line of thinking one could consider cases like (E^n)^n or even with repeated applications of the Cartesian product operation. Thus, in the case of (E^n)^n, one can think of different gamblers each having n-many dices in a cup and tossing these n-many dices simultaneously.
Thus we have something like the following structure for an empirical theory of classical probability: CPT(T) iff T=<G,E,X,n,S,P*>, with ‘G’ as the set of generators producing out of E events according to the layout of the set X in a static (deterministic) manner. Here the set E is the set of basic events. The set X is a ‘typified set’ constructed out of the set E with t-many applications of the Cartesian operation starting with E, then E^n1, then (E^n1)^n2, …. . ‘n’ denotes the number of repetitions, which determines the length of a sequence ‘S’. ‘P*’ represents the ’empirical probability’ which approaches the theoretical probability P while n is becoming ‘big’. P* is realized as a tuple of tuples according to the layout of the set X where each element in the range of a tuple represents the ‘number of occurrences’ of a certain event out of X.
Example: If there is a set E = {0,1} with the layout X=(E^2)^2 then we have two groups with two generators each: <<G1, G2>,<G3,G4>>. Every generator G_i produces events out of E. In one state i this could look like <<0, 0>,<1,0>>. As part of a sequence S this would look like S = <….,(<<0, 0>,<1,0>>,i), … > telling that in the i-th state of S there is an occurrence of events like shown. The empirical probability function P* has a corresponding layout P* = <<m1, m2>,<m3,m4>> with the m_j as ‘counter’ which are counting the occurrences of the different types of events as m_j =<c_e1, …, c_er>. In the example there are two different types of events occurring {0,1} which requires two counters c_0 and c_1, thus we would have m_j =<c_0, c_1>, which would induce for this example the global counter structure: P* = <<<c_0, c_1>, <c_0, c_1>>,<<c_0, c_1>,<c_0, c_1>>>. If the generators are all the same then the set of basic events E is the same and in theory the theoretical probability function P: E —> R+ would induce the same global values for all generators. But in the empirical case, if the theoretical probability function P is not known, then one has to count and below the ‘magic big n’ the values of the counter of the empirical probability function can be different.
This format of the empirical classical probability theory CPT can handle the case of ‘different generators‘ which produce events out of the same basic set E but with different probabilities, which can be counted by the empirical probability function P*. A prominent case of different probabilities with the same set of events is the case of manipulations of generators (a coin, a dice, a roulette wheel, …) to deceive other people.
In the examples mentioned so far the probabilities of the basic events as well as the complex events can be different in different generators, but are nevertheless ‘static’, not changing. Looking to generators like ‘tossing a coin’, ‘tossing a dice’ this seams to be sound. But what if we look to other types of generators like ‘biological systems’ which have to ‘decide’ which possible options of acting they ‘choose’? If the set of possible actions A is static, then the probability of selecting one action a out of A will usually depend from some ‘inner states’ IS of the biological system. These inner states IS need at least the following two components:(i) an internal ‘representation of the possible actions’ IS_A as well (ii) a finite set of ‘preferences’ IS_Pref. Depending from the preferences the biological system will select an action IS_a out of IS_A and then it can generate an action a out of A.
If biological systems as generators have a ‘static’ (‘deterministic’) set of preferences IS_Pref, then they will act like fixed generators for ‘tossing a coin’, ‘tossing a dice’. In this case nothing will change. But, as we know from the empirical world, biological systems are in general ‘adaptive’ systems which enables two kinds of adaptation: (i) ‘structural‘ adaptation like in biological evolution and (ii) ‘cognitive‘ adaptation as with higher organisms having a neural system with a brain. In these systems (example: homo sapiens) the set of preferences IS_Pref can change in time as well as the internal ‘representation of the possible actions’ IS_A. These changes cause a shift in the probabilities of the events manifested in the realized actions!
If we allow possible changes in the terms ‘G’ and ‘E’ to ‘G+’ and ‘E+’ then we have no longer a ‘classical’ probability theory CPT. This new type of probability theory we can call ‘non-classic’ probability theory NCPT. A short notation could be: NCPT(T) iff T=<G+,E+,X,n,S,P*> where ‘G+’ represents an adaptive biological system with changing representations for possible Actions A* as well as changing preferences IS_Pref+. The interesting question is, whether a quantum logic approach QLPT is a possible realization of such a non-classical probability theory. While it is known that the QLPT works for physical matters, it is an open question whether it works for biological systems too.
REMARK: switching from static generators to adaptive generators induces the need for the inclusion of the environment of the adaptive generators. ‘Adaptation’ is generally a capacity to deal better with non-static environments.