
eJournal: uffmm.org
ISSN 2567-6458, 6.February 2019
Email: info@uffmm.org
Author: Gerd Doeben-Henisch
Email: gerd@doeben-henisch.de
CONTEXT
An overview of the enhanced AAI theory version 2 you can find here. In this post we talk about the tenth chapter dealing with Measuring Usability
MEASURING USABILITY
As has been delineated in the post “Usability and Usefulness” statements about the quality of the usability of some assisting actor are based on some kinds of measurement: mapping some target (here the interactions of an executive actor with some assistive actor) into some predefined norm (e.g. ‘number of errors’, ‘time needed for completion’, …). These remarks are here embedded in a larger perspective following Dumas and Fox (2008).
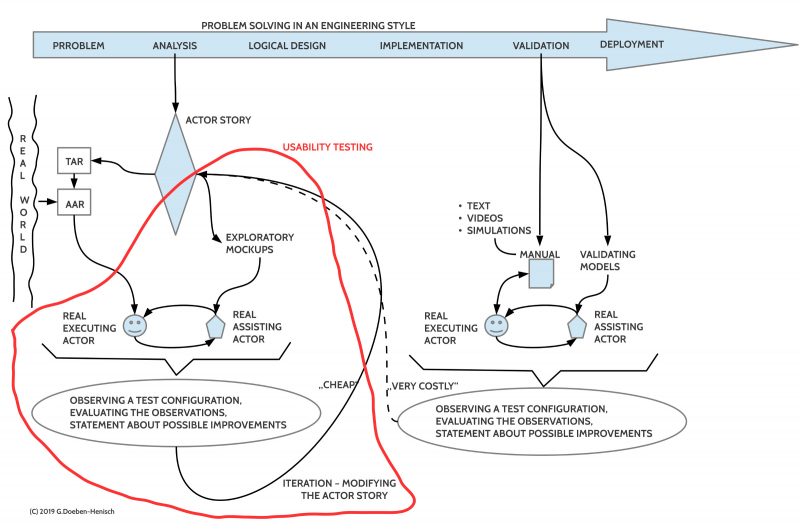
From the three main types of usability testing with regard to the position in the life-cycle of a system we focus here primarily on the usability testing as part of the analysis phase where the developers want to get direct feedback for the concepts embedded in an actor story. Depending from this feedback the actor story and its related models can become modified and this can result in a modified exploratory mock-up for a new test. The challenge is not to be ‘complete’ in finding ‘disturbing’ factors during an interaction but to increase the probability to detect possible disturbing factors by facing the symbolically represented concepts of the actor story with a sample of real world actors. Experiments point to the number of 5-10 test persons which seem to be sufficient to detect the most severe disturbing factors of the concepts.
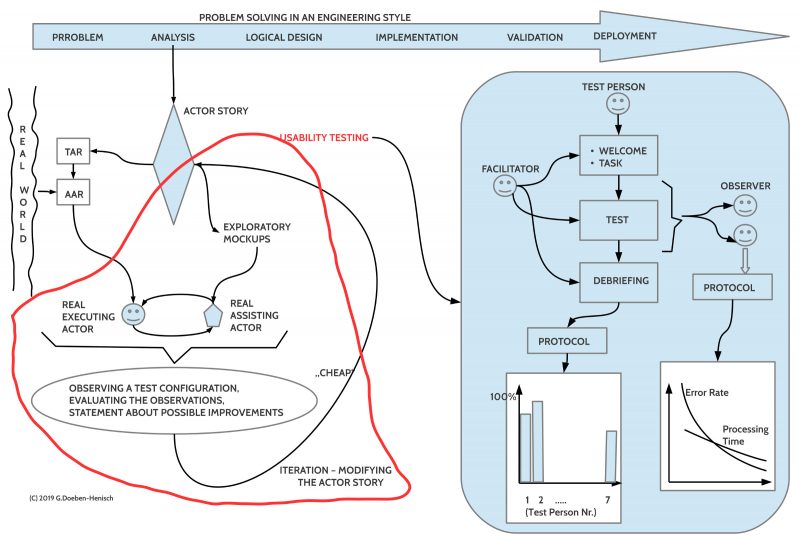
A good description of usability testing can be found in the book Lauesen (2005), especially chapters 1 +13. According to this one can infer the following basic schema for a usability test:
- One needs 5 – 10 test persons whose input-output profile (AAR) comes close to the profile (TAR) required by the actor story.
- One needs a mock-up of the assistive actor; this mock-up should correspond ‘sufficiently well’ with the input-output profile (TAR) required by the actor story. In the simplest case one has a ‘paper model’, whose sheets can be changed on demand.
- One needs a facilitator who is receiving the test person, introduces the test person into the task (orally and/ or by a short document (less than a page)), then accompanies the test without interacting further with the test person until the end of the test. The end is either reached by completing the task or by reaching the end of a predefined duration time.
- After the test person has finished the test a debriefing happens by interrogating the test person about his/ her subjective feelings about the test. Because interviews are always very fuzzy and not very reliable one should keep this interrogation simple, short, and associated with concrete points. One strategy could be to ask the test person first about the general feeling: Was it ‘very good’, ‘good’, ‘OK’, ‘undefined’, ‘not OK’, ‘bad’, ‘very bad’ (+3 … 0 … -3). If the stated feeling is announced then one can ask back which kinds of circumstances caused these feelings.
- During the test at least two observers are observing the behavior of the test person. The observer are using as their ‘norm’ the actor story which tells what ‘should happen in the ideal case’. If a test person is deviating from the actor story this will be noted as a ‘deviation of kind X’, and this counts as an error. Because an actor story in the mathematical format represents a graph it is simple to quantify the behavior of the test person with regard to how many nodes of a solution path have been positively passed. This gives a count for the percentage of how much has been done. Thus the observer can deliver data about at least the ‘percentage of task completion’, ‘the number (and kind) of errors by deviations’, and ‘the processing time’. The advantage of having the actor story as a norm is that all observers will use the same ‘observation categories’.
- From the debriefing one gets data about the ‘good/ bad’ feelings on a scale, and some hints what could have caused the reported feelings.
STANDARDS – CIF (Common Industry Format)
There are many standards around describing different aspects of usability testing. Although standards can help in practice from the point of research standards are not only good, they can hinder creative alternative approaches. Nevertheless I myself are looking to standards to check for some possible ‘references’. One standard I am using very often is the “Common Industry Format (CIF)” for usability reporting. It is an ISO standard (ISO/IEC 25062:2006) since 2006. CIF describes a method for reporting the findings of usability tests that collect quantitative measurements of user performance. CIF does not describe how to carry out a usability test, but it does require that the test include measurements of the application’s effectiveness and efficiency as well as a measure of the users’ satisfaction. These are the three elements that define the concept of usability.
Applied to the AAI paradigm these terms are fitting well.
Effectiveness in CIF is targeting the accuracy and completeness with which users achieve their goal. Because the actor story in AAI his represented as a graph where the individual paths represents a way to approach a defined goal one can measure directly the accuracy by comparing the ‘observed path’ in a test and the ‘intended ideal path’ in the actor story. In the same way one can compute the completeness by comparing the observed path and the intended ideal path of the actor story.
Efficiency in CIF covers the resources expended to achieve the goals. A simple and direct measure is the measuring of the time needed.
Users’ satisfaction in CIF means ‘freedom from discomfort’ and ‘positive attitudes towards the use of the product‘. These are ‘subjective feelings’ which cannot directly be observed. Only ‘indirect’ measures are possible based on interrogations (or interactions with certain tasks) which inherently are fuzzy and not very reliable. One possibility how to interrogate is mentioned above.
Because the term usability in CIF is defined by the before mentioned terms of effectiveness, efficiency as well as users’ satisfaction, which in turn can be measured in many different ways the meaning of ‘usability’ is still a bit vague.
DYNAMIC ACTORS – CHANGING CONTEXTS
With regard to the AAI paradigm one has further to mention that the possibility of adaptive, learning systems embedded in dynamic, changing environments requires for a new type of usability testing. Because learning actors change by every exercise one should run a test several times to observe how the dynamic learning rates of an actor are developing in time. In such a dynamic framework a system would only be ‘badly usable‘ when the learning curves of the actors can not approach a certain threshold after a defined ‘typical learning time’. And, moreover, there could be additional effects occurring only in a long-term usage and observation, which can not be measured in a single test.
REFERENCES
- ISO/IEC 25062:2006(E)
- Joseph S. Dumas and Jean E. Fox. Usability testing: Current practice
and future directions. chapter 57, pp.1129 – 1149, in J.A. Jacko and A. Sears, editors, The Human-Computer Interaction Handbook. Fundamentals, Evolving Technologies, and Emerging Applications. 2nd edition, 2008 - S. Lauesen. User Interface Design. A software Engineering Perspective.
Pearson – Addison Wesley, London et al., 2005
