In the last months I was engaged with the topic of text-generating algorithms and the possible impact for a scientific discourse (some first notices to this discussion you can find here (https://www.uffmm.org/2023/08/24/homo-sapiens-empirical-and-sustained-empirical-theories-emotions-and-machines-a-sketch/)). In this context it is important to clarify the role and structure of human actors as well as the concept of Intelligence. Meanwhile I have abandoned the word Intelligence completely because the inflationary use in today mainstream pulverises any meaning. Even in one discipline — like psychology — you can find many different concepts. In this context I have read the book of Stanovich et.al to have a prominent example of using the concept of intelligence, there combined with the concept of rationality, which is no less vague.
Introduction
The book “The Rationality Quotient” from 2016 represents not the beginning of a discourse but is a kind of summary of a long lasting discourse with many publications before. This makes this book interesting, but also difficult to read in the beginning, because the book is using nearly on every page theoretical terms, which are assumed to be known to the reader and cites other publications without giving sufficient explanations why exactly these cited publications are important. This is no argument against this book but sheds some light on the reader, who has to learn a lot to understand the text.
A text with the character of summing up its subject is good, because it has a confirmed meaning about the subject which enables a kind of clarity which is typical for that state of elaborated point of view.
In the following review it is not the goal to give a complete account of every detail of this book but only to present the main thesis and then to analyze the used methods and the applied epistemological framework.
Main Thesis of the Book
The reviewing starts with the basic assumptions and the main thesis.
FIGURE 1 : The beginning. Note: the number ‘2015’ has to be corrected to ‘2016’.
FIGURE 2 : First outline of cognition. Note: the number ‘2015’ has to be corrected to ‘2016’.
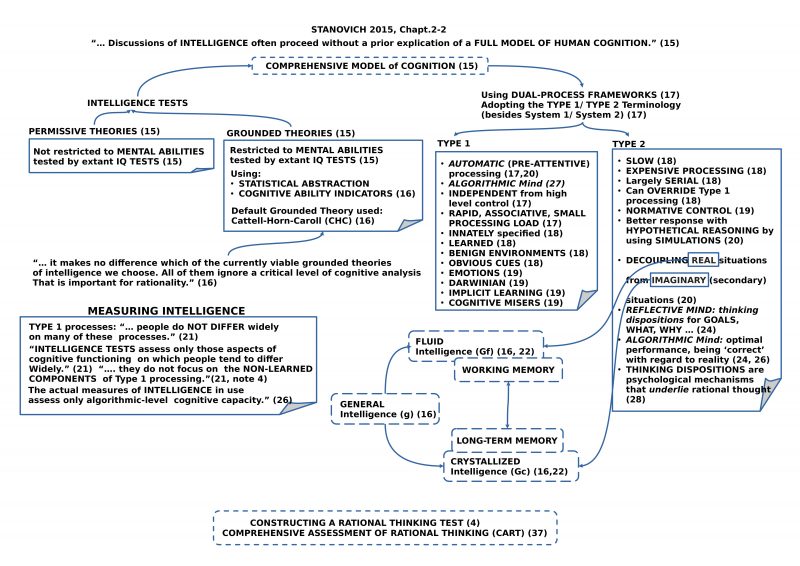
As mentioned in the introduction you will in the book not find a real overview about the history of psychological research dealing with the concept of Intelligence and also no overview about the historical discourse to the concept of Rationality, whereby the last concept has also a rich tradition in Philosophy. Thus, somehow you have to know it.
There are some clear warnings with regard to the fuzziness of the concept rationality (p.3) as well as to the concept of intelligence (p.15). From a point of view of Philosophy of Science it could be interesting to know what the circumstances are which are causing such a fuzziness, but this is not a topic of the book. The book talks within its own selected conceptual paradigm. Being in the dilemma, of what kind of intelligence paradigm one wants to use, the book has decided to work with the Cattell-Horn-Carroll (CTC) paradigm, which some call a theory. [1]
Directly from the beginning it is explained that the discussion of Intelligence is missing a clear explanation of the full human model of cognition (p.15) and that intelligence tests therefore are mostly measuring only parts of human cognitive functions. (p.21)
Thus let us have a more detailed look to the scenario.
[1] For a first look to the Cattell–Horn–Carroll theory see: https://en.wikipedia.org/wiki/Cattell%E2%80%93Horn%E2%80%93Carroll_theory, a first overview.
Which point of View?
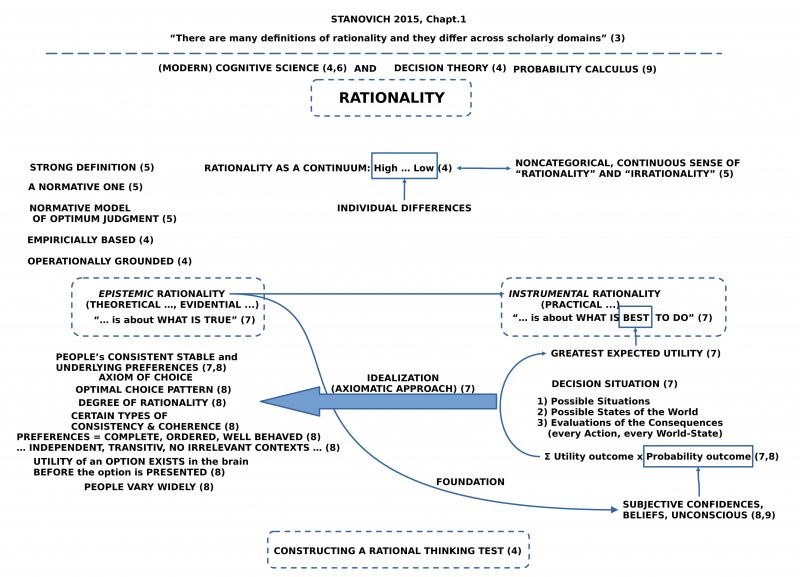
The book starts with a first characterization of the concept of Rationality within a point of view which is not really clear. From different remarks one gets some hints to modern Cognitive Science (4,6), to Decision Theory (4) and Probability Calculus (9), but a clear description is missing.
And it is declared right from the beginning, that the main aim of the book is the Construction of a rational Thinking Test (4), because for the authors the used Intelligence Tests — later reduced to the Carroll-Horn-Carroll (CHC) type of intelligence test (16) — are too narrow in what they are measuring (15, 16, 21).
Related to the term Rationality the book characterizes some requirements which the term rationality should fulfill (e.g. ‘Rationality as a continuum’ (4), ’empirically based’ (4), ‘operationally grounded’ (4), a ‘strong definition’ (5), a ‘normative one’ (5), ‘normative model of optimum judgment’ (5)), but it is more or less open, what these requirements imply and what tacit assumptions have to be fulfilled, that this will work.
The two requirements ’empirically based’ as well as ‘operationally grounded’ point in the direction of an tacitly assumed concept of an empirical theory, but exactly this concept — and especially in association with the term cognitive science — isn’t really clear today.
Because the authors make in the next pages a lot of statements which claim to be serious, it seems to be important for the discussion in this review text to clarify the conditions of the ‘meaning of language expressions’ and of being classified as ‘being true’.
If we assume — tentatively — that the authors assume a scientific theory to be primarily a text whose expressions have a meaning which can transparently be associated with an empirical fact and if this is the case, then the expression will be understood as being grounded and classified as true, then we have characterized a normal text which can be used in everyday live for the communication of meanings which can become demonstrated as being true.
Is there a difference between such a ‘normal text’ and a ‘scientific theory’? And, especially here, where the context should be a scientific theory within the discipline of cognitive science: what distinguishes a normal text from a ‘scientific theory within cognitive science’?
Because the authors do not explain their conceptual framework called cognitive science we recur here to a most general characterization [2,3] which tells us, that cognitive science is not a single discipline but an interdisciplinary study which is taking from many different disciplines. It has not yet reached a state where all used methods and terms are embedded in one general coherent framework. Thus the relationship of the used conceptual frameworks is mostly fuzzy, unclear. From this follows directly, that the relationship of the different terms to each other — e.g. like ‘underlying preferences’ and ‘well ordered’ — is within such a blurred context rather unclear.
Even the simple characterization of an expression as ‘having an empirical meaning’ is unclear: what are the kinds of empirical subjects and the used terms? According to the list of involved disciplines the disciplines linguistics [4], psychology [5] or neuroscience [6] — besides others — are mentioned. But every of these disciplines is itself today a broad field of methods, not integrated, dealing with a multifaceted subject.
Using an Auxiliary Construction as a Minimal Point of Reference
Instead of becoming somehow paralyzed from these one-and-all characterizations of the individual disciplines one can try to step back and taking a look to basic assumptions about empirical perspectives.
If we take a group of HumanObservers which shall investigate these subjects we could make the following assumptions:
Empirical Linguistics is dealing with languages, spoken as well as written by human persons, within certain environments, and these can be observed as empirical entities.
Empirical Psychology is dealing with the behavior of human persons (a kind of biological systems) within certain environments, and these can be observed.
Empirical Neuroscience is dealing with the brain as part of a body which is located in some environment, and this all can be observed.
The empirical observations of certain kinds of empirical phenomena can be used to define more abstract concepts, relations, and processes. These more abstract concepts, relations, and processes have ‘as such’ no empirical meaning! They constitute a formal framework which has to become correlated with empirical facts to get some empirical meaning. As it is known from philosophy of science [7] the combination of empirical concepts within a formal framework of abstracts terms can enable ‘abstract meanings’ which by logical conclusions can produce statements which are — in the moment of stating them — not empirically true, because ‘real future’ has not yet happened. And on account of the ‘generality’ of abstract terms compared to the finiteness and concreteness of empirical facts it can happen, that the inferred statements never will become true. Therefore the mere usage of abstract terms within a text called scientific theory does not guarantee valid empirical statements.
And in general one has to state, that a coherent scientific theory including e.g. linguistics, psychology and neuroscience, is not yet in existence.
To speak of cognitive science as if this represents a clearly defined coherent discipline seems therefore to be misleading.
This raises questions about the project of a constructing a coherent rational thinking test (CART).
[2] See ‘cognitive science’ in wikipedia: https://en.wikipedia.org/wiki/Cognitive_science
[3] See too ‘cognitive science’ in the Stanford Encyclopedia of Philosophy: https://plato.stanford.edu/entries/cognitive-science/
[4] See ‘linguistics’ in wikipedia: https://en.wikipedia.org/wiki/Linguistics
[5] See ‘psychology’ in wikipedia: https://en.wikipedia.org/wiki/Psychology
[6] See ‘neuroscience’ in wikipedia: https://en.wikipedia.org/wiki/Neuroscience
[7] See ‘philosophy of science’ in wikipedia: https://en.wikipedia.org/wiki/Philosophy_of_science
‘CART’ TEST FRAMEWORK – A Reconstruction from the point of View of Philosophy of Science
Before I will dig deeper into the theory I try to understand the intended outcome of this theory as some point of reference. The following figure 3 gives some hints.
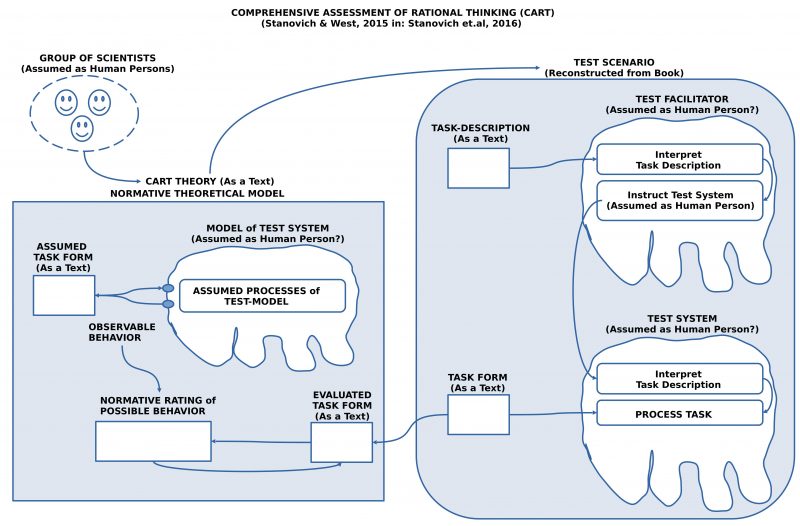
FIGURE 3 : Outline of the Test Framework based on the Appendix in Stanovich et.al 2016. This Outline is a Reconstruction by the author of this review.
It seems to be important to distinguish at least three main parts of the whole scientific endeavor:
The group of scientists which has decided to process a certain problem.
The generated scientific theory as a text.
The description of a CART Test, which describes a procedure, how the abstract terms of the theory can be associated with real facts.
From the group of scientists (Stanovich et al.) we know that they understand themselves as cognitive scientists (without having a clear characterization, what this means concretely).
The intended scientific theory as a text is here assumed to be realized in the book, which is here the subject of a review.
The description of a CART Test is here taken from the appendix of the book.
To understand the theory it is interesting to see, that in the real test the test system (assumed here as a human person) has to read (and hear?) a instruction, how to proceed with a task form, and then the test system (a human person) has to process the test form in the way it has understood the instructions and the test form as it is.
The result is a completed test form.
And it is then this completed test form which will be rated according to the assumed CART theory.
This complete paradigm raises a whole bunch of questions which to answer here in full is somehow out of range.
Mix-Up of Abstract Terms
Because the Test Scenario presupposes a CART theory and within this theory some kind of a model of intended test users it can be helpful to have a more closer look to this assumed CART model, which is located in a person.
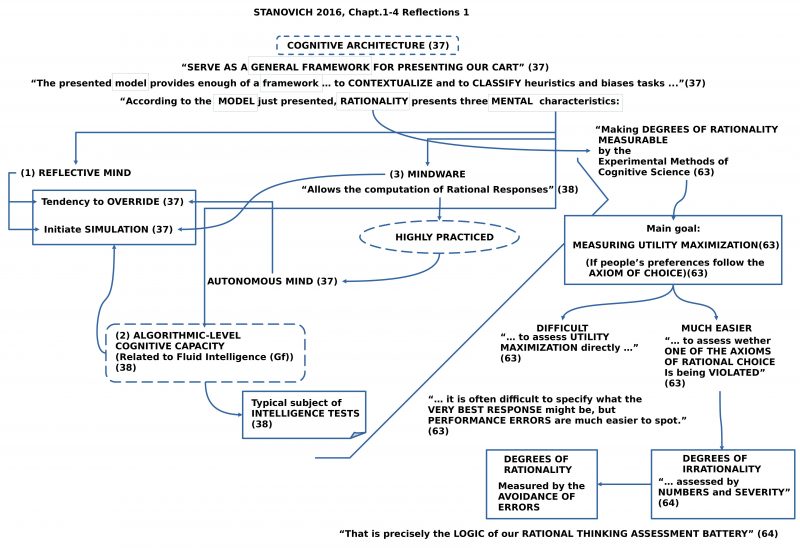
FIGURE 4 : General outline of the logic behind CART according to Stanovich et al. (2016).
The presented cognitive architecture shall present a framework for the CART (Comprehensive Assessment of Rational Thinking), whereby this framework is including a model. The model is not only assumed to contextualize and classify heuristics and tasks, but it also presents Rationality in a way that one can deduce mental characteristics included in rationality.(cf. 37)
Because the term Rationality is not an individual empirical fact but an abstract term of a conceptual framework, this term has as such no meaning. The meaning of this abstract term has to be arranged by relations to other abstract terms which themselves are sufficiently related to concrete empirical statements. And these relations between abstract terms and empirical facts (represented as language expressions) have to be represented in a manner, that it is transparent how the the measured facts are related to the abstract terms.
Here Stanovich et al. is using another abstract term Mind, which is associated with characteristics called mental characteristics: Reflective mind, Algorithmic Level, and Mindware.
And then the text tells that Rationality is presenting mental characteristics. What does this mean? Is rationality different from the mind, who has some characteristics, which can be presented from rationality using somehow the mind, or is rationality nevertheless part of the mind and manifests themself in these mental characteristics? But what kind of the meaning could this be for an abstract term like rationality to be part of the mind? Without an explicit model associated with the term Mind which arranges the other abstract term Rationality within this model there exists no meaning which can be used here.
These considerations are the effect of a text, which uses different abstract terms in a way, which is rather unclear. In a scientific theory this should not be the case.
Measuring Degrees of Rationality
In the beginning of chapter 4 Stanovich et al. are looking back to chapter 1. Here they built up a chain of arguments which illustrate some general perspective (cf. 63):
Rationality has degrees.
These degrees of rationality can be measured.
Measurement is realized by experimental methods of cognitive science.
The measuring is based on the observable behavior of people.
The observable behavior can manifest whether the individual actor (a human person) follows assumed preferences related to an assumed axiom of choice.
Observable behavior which is classified as manifesting assumed internal preferences according to an assumed internal axiom of choice can show descriptive and procedural invariance.
Based on these deduced descriptive and procedural invariance, it can be inferred further, that these actors are behaving as if they are maximizing utility.
It is difficult to assess utility maximization directly.
It is much easier to assess whether one of the axioms of rational choice is being violated.
These statements characterize the Logic of the CART according to Stanovich et al. (cf.64)
A major point in this argumentation is the assumption, that observable behavior is such, that one can deduce from the properties of this behavior those attributes/ properties, which point (i) to an internal model of an axiom of choice, (ii) to internal processes, which manifest the effects of this internal model, (iii) to certain characteristics of these internal processes which allow the deduction of the property of maximizing utility or not.
These are very strong assumptions.
If one takes further into account the explanations from the pages 7f about the required properties for an abstract term axiom of choice (cf. figure 1) then these assumptions appear to be very demanding.
Can it be possible to extract the necessary meaning out of observable behavior in a way, which is clear enough by empirical standards, that this behavior shows property A and not property B ?
As we know from the description of the CART in the appendix of the book (cf. figure 3) the real behavior assumed for an CART is the (i) reading (or hearing?) of an instruction communicated by ordinary English, and then (ii) a behavior deduced from the understanding of the instruction, which (iii) manifests themself in the reading of a form with a text and filling out this form in predefined positions in a required language.
This described procedure is quite common throughout psychology and similar disciplines. But it is well known, that the understanding of language instructions is very error-prone. Furthermore, the presentation of a task as a text is inevitably highly biased and additionally too very error-prone with regard to the understanding (this is a reason why in usability testing purely text-based tests are rather useless).
The point is, that the empirical basis is not given as a protocol of observations of language free behavior but of a behavior which is nearly completely embedded in the understanding and handling of texts. This points to the underlying processes of text understanding which are completelyinternal to the actor. There exists no prewired connection between the observable strings of signs constituting a text and the possible meaning which can be organized by the individual processes of text understanding.
Stopping Here
Having reached this point of reading and trying to understand I decided to stop here: to many questions on all levels of a scientific discourse and the relationships between main concepts and terms appear in the book of Stanovich et al. to be not clear enough. I feel therefore confirmed in my working hypothesis from the beginning, that the concept of intelligence today is far too vague, too ambiguous to contain any useful kernel of meaning any more. And concepts like Rationality, Mind (and many others) seem to do not better.
Chatting with chatGPT4
Since April 2023 I have started to check the ability of chatGPT4 to contribute to a philosophical and scientific discourse. The working hypothesis is, that chatGPT4 is good in summarizing the common concepts, which are used in public texts, but chatGPT is not able for critical evaluations, not for really new creative ideas and in no case for systematic analysis of used methods, used frameworks, their interrelations, their truth-conditons and much more, what it cannot. Nevertheless, it is a good ‘common sense check’. Until now I couldn’t learn anything new from these chats.
If you have read this review with all the details and open questions you will be perhaps a little bit disappointed about the answers from chatGPT4. But keep calm: it is a bit helpful.
Since the release of the chatbot ‘chatGPT’ to the larger public, a kind of ‘earthquake’ has been going through the media, worldwide, in many areas, from individuals to institutions, companies, government agencies …. everyone is looking for the ‘chatGPT experience’. These reactions are amazing, and frightening at the same time.
Remark: The text of this post represents a later ‘stage’ of my thinking about the usefulness of the chatGPT algorithm, which started with my first reflections in the text entitled “chatGBT about Rationality: Emotions, Mystik, Unconscious, Conscious, …” from 15./16.January 2023. The main text to this version is an English translation from an originally German text partially generated with the www.DeepL.com/Translator (free version).
FORM
The following lines form only a short note, since it is hardly worthwhile to discuss a ‘surface phenomenon’ so intensively, when the ‘deep structures’ should be explained. Somehow the ‘structures behind chatGPT’ seem to interest hardly anybody (I do not mean technical details of the used algorithms).
chatGPT as an object
The chatbot named ‘chatGPT’ is a piece of software, an algorithm that (i) was invented and programmed by humans. When (ii) people ask it questions, then (iii) it searches the database of documents known to it, which in turn have been created by humans, (iv) for text patterns that have a relation to the question according to certain formal criteria (partly given by the programmers). These ‘text finds’ are (v) also ‘arranged’ according to certain formal criteria (partly given by the programmers) into a new text, which (vi) should come close to those text patterns, which a human reader is ‘used’ to accept as ‘meaningful’.
Text surface – text meaning – truthfulness
A normal human being can distinguish – at least ‘intuitively’ – between the (i) ‘strings’ used as ‘expressions of a language’ and those (ii) ‘knowledge elements’ (in the mind of the hearer-speaker) which are as such ‘independent’ of the language elements, but which (iii) can be ‘freely associated’ by speakers-hearers of a language, so that the correlated ‘knowledge elements’ become what is usually called the ‘meaning’ of the language elements. [1] Of these knowledge elements (iv), every language participant already ‘knows’ ‘pre-linguistically’, as a learning child [2], that some of these knowledge elements are ‘correlatable’ with circumstances of the everyday world under certain circumstances. And the normal language user also ‘intuitively’ (automatically, unconsciously) has the ability to assess such correlation – in the light of the available knowledge – as (v) ‘possible’ or (vi) as rather ‘improbable’ or (vi) as ‘mere fancifulness’.”[3]
The basic ability of a human being to be able to establish a ‘correlation’ of meanings with (intersubjective) environmental facts is called – at least by some – philosophers ‘truth ability’ and in the execution of truth ability one then also can speak of ‘true’ linguistic utterances or of ‘true statements’.[5]
Distinctions like ‘true’, ‘possibly true’, ‘rather not true’ or ‘in no case true’ indicate that the reality reference of human knowledge elements is very diverse and ‘dynamic’. Something that was true a moment ago may not be true the next moment. Something that has long been dismissed as ‘mere fantasy’ may suddenly appear as ‘possible’ or ‘suddenly true’. To move in this ‘dynamically correlated space of meaning’ in such a way that a certain ‘inner and outer consistency’ is preserved, is a complex challenge, which has not yet been fully understood by philosophy and the sciences, let alone even approximately ‘explained’.
The fact is: we humans can do this to a certain extent. Of course, the more complex the knowledge space is, the more diverse the linguistic interactions with other people become, the more difficult it becomes to completely understand all aspects of a linguistic statement in a situation.
‘Air act’ chatGPT
Comparing the chatbot chatGPT with these ‘basic characteristics’ of humans, one can see that chatGPT can do none of these things. (i) It cannot ask questions meaningfully on its own, since there is no reason why it should ask (unless someone induces it to ask). (ii) Text documents (of people) are sets of expressions for him, for which he has no independent assignment of meaning. So he could never independently ask or answer the ‘truth question’ – with all its dynamic shades. He takes everything at ‘face value’ or one says right away that he is ‘only dreaming’.
If chatGPT, because of its large text database, has a subset of expressions that are somehow classified as ‘true’, then the algorithm can ‘in principle’ indirectly determine ‘probabilities’ that other sets of expressions that are not classified as ‘true’ then do ‘with some probability’ appear to be ‘true’. Whether the current chatGPT algorithm uses such ‘probable truths’ explicitly is unclear. In principle, it translates texts into ‘vector spaces’ that are ‘mapped into each other’ in various ways, and parts of these vector spaces are then output again in the form of a ‘text’. The concept of ‘truth’ does not appear in these mathematical operations – to my current knowledge. If, then it would be also only the formal logical concept of truth [4]; but this lies with respect to the vector spaces ‘above’ the vector spaces, forms with respect to these a ‘meta-concept’. If one wanted to actually apply this to the vector spaces and operations on these vector spaces, then one would have to completely rewrite the code of chatGPT. If one would do this – but nobody will be able to do this – then the code of chatGPT would have the status of a formal theory (as in mathematics) (see remark [5]). From an empirical truth capability chatGPT would then still be miles away.
Hybrid illusory truths
In the use case where the algorithm named ‘chatGPT’ uses expression sets similar to the texts that humans produce and read, chatGPT navigates purely formally and with probabilities through the space of formal expression elements. However, a human who ‘reads’ the expression sets produced by chatGPT automatically (= unconsciously!) activates his or her ‘linguistic knowledge of meaning’ and projects it into the abstract expression sets of chatGBT. As one can observe (and hears and reads from others), the abstract expression sets produced by chatGBT are so similar to the usual text input of humans – purely formally – that a human can seemingly effortlessly correlate his meaning knowledge with these texts. This has the consequence that the receiving (reading, listening) human has the ‘feeling’ that chatGPT produces ‘meaningful texts’. In the ‘projection’ of the reading/listening human YES, but in the production of chatGPT NO. chatGBT has only formal expression sets (coded as vector spaces), with which it calculates ‘blindly’. It does not have ‘meanings’ in the human sense even rudimentarily.
Back to the Human?
(Last change: 27.February 2023)
How easily people are impressed by a ‘fake machine’ to the point of apparently forgetting themselves in face of the machine by feeling ‘stupid’ and ‘inefficient’, although the machine only makes ‘correlations’ between human questions and human knowledge documents in a purely formal way, is actually frightening [6a,b], [7], at least in a double sense: (i)Instead of better recognizing (and using) one’s own potentials, one stares spellbound like the famous ‘rabbit at the snake’, although the machine is still a ‘product of the human mind’. (ii) This ‘cognitive deception’ misses to better understand the actually immense potential of ‘collective human intelligence’, which of course could then be advanced by at least one evolutionary level higher by incorporating modern technologies. The challenge of the hour is ‘Collective Human-Machine Intelligence’ in the context of sustainable development with priority given to human collective intelligence. The current so-called ‘artificial (= machine) intelligence’ is only present by rather primitive algorithms. Integrated into a developed ‘collective human intelligence’ quite different forms of ‘intelligence’ could be realized, ones we currently can only dream of at most.
Commenting on other articles from other authors about chatGPT
(Last change: 14.April 2023)
[7], [8],[9],[11],[12],[13],[14]
Comments
(Last change: 3.April 2023)
wkp-en: en.wikipedia.org
[1] In the many thousands of ‘natural languages’ of this world one can observe how ‘experiential environmental facts’ can become ‘knowledge elements’ via ‘perception’, which are then correlated with different expressions in each language. Linguists (and semioticians) therefore speak here of ‘conventions’, ‘freely agreed assignments’.
[2] Due to physical interaction with the environment, which enables ‘perceptual events’ that are distinguishable from the ‘remembered and known knowledge elements’.
[3] The classification of ‘knowledge elements’ as ‘imaginations/ fantasies’ can be wrong, as many examples show, like vice versa, the classification as ‘probably correlatable’ can be wrong too!
[4] Not the ‘classical (Aristotelian) logic’ since the Aristotelian logic did not yet realize a stricCommenting on other articles from other authors about chatGPTt separation of ‘form’ (elements of expression) and ‘content’ (meaning).
[5] There are also contexts in which one speaks of ‘true statements’ although there is no relation to a concrete world experience. For example in the field of mathematics, where one likes to say that a statement is ‘true’. But this is a completely ‘different truth’. Here it is about the fact that in the context of a ‘mathematical theory’ certain ‘basic assumptions’ were made (which must have nothing to do with a concrete reality), and one then ‘derives’ other statements starting from these basic assumptions with the help of a formal concept of inference (the formal logic). A ‘derived statement’ (usually called a ‘theorem’), also has no relation to a concrete reality. It is ‘logically true’ or ‘formally true’. If one would ‘relate’ the basic assumptions of a mathematical theory to concrete reality by – certainly not very simple – ‘interpretations’ (as e.g. in ‘applied physics’), then it may be, under special conditions, that the formally derived statements of such an ’empirically interpreted abstract theory’ gain an ’empirical meaning’, which may be ‘correlatable’ under certain conditions; then such statements would not only be called ‘logically true’, but also ’empirically true’. As the history of science and philosophy of science shows, however, the ‘transition’ from empirically interpreted abstract theories to empirically interpretable inferences with truth claims is not trivial. The reason lies in the used ‘logical inference concept’. In modern formal logic there are almost ‘arbitrarily many’ different formal inference terms possible. Whether such a formal inference term really ‘adequately represents’ the structure of empirical facts via abstract structures with formal inferences is not at all certain! This pro’simulation’blem is not really clarified in the philosophy of science so far!
[6a] Weizenbaum’s 1966 chatbot ‘Eliza’, despite its simplicity, was able to make human users believe that the program ‘understood’ them even when they were told that it was just a simple algorithm. See the keyword ‚Eliza‘ in wkp-en: https://en.wikipedia.org/wiki/ELIZA
[6b] Joseph Weizenbaum, 1966, „ELIZA. A Computer Program For the Study of Natural Language. Communication Between Man And Machine“, Communications of the ACM, Vol.9, No.1, January 1966, URL: https://cse.buffalo.edu/~rapaport/572/S02/weizenbaum.eliza.1966.pdf . Note: Although the program ‘Eliza’ by Weizenbaum was very simple, all users were fascinated by the program because they had the feeling “It understands me”, while the program only mirrored the questions and statements of the users. In other words, the users were ‘fascinated by themselves’ with the program as a kind of ‘mirror’.
[7] Ted Chiang, 2023, “ChatGPT Is a Blurry JPEG of the Web. OpenAI’s chatbot offers paraphrases, whereas Google offers quotes. Which do we prefer?”, The NEW YORKER, February 9, 2023. URL: https://www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web . Note: Chang looks to the chatGPT program using the paradigm of a ‘compression algorithm’: the abundance of information is ‘condensed/abstracted’ so that a slightly blurred image of the text volumes is created, not a 1-to-1 copy. This gives the user the impression of understanding at the expense of access to detail and accuracy. The texts of chatGPT are not ‘true’, but they ‘mute’.
[8] Dietmar Hansch, 2023, “The more honest name would be ‘Simulated Intelligence’. Which deficits bots like chatGBT suffer from and what that must mean for our dealings with them.”, FAZ Frankfurter Allgemeine Zeitung, March 1, 2023, p.N1 . Note: While Chiang (see [7]) approaches the phenomenon chatGPT with the concept ‘compression algorithm’ Hansch prefers the terms ‘statistical-incremental learning’ as well as ‘insight learning’. For Hansch, insight learning is tied to ‘mind’ and ‘consciousness’, for which he postulates ‘equivalent structures’ in the brain. Regarding insight learning, Hansch further comments “insight learning is not only faster, but also indispensable for a deep, holistic understanding of the world, which grasps far-reaching connections as well as conveys criteria for truth and truthfulness.” It is not surprising then when Hansch writes “Insight learning is the highest form of learning…”. With reference to this frame of reference established by Hansch, he classifies chatGPT in the sense that it is only capable of ‘statistical-incremental learning’. Further, Hansch postulates for humans, “Human learning is never purely objective, we always structure the world in relation to our needs, feelings, and conscious purposes…”. He calls this the ‘human reference’ in human cognition, and it is precisely this what he also denies for chatGPT. For common designation ‘AI’ as ‘Artificial Intelligence’ he postulates that the term ‘intelligence’ in this word combination has nothing to do with the meaning we associate with ‘intelligence’ in the case of humans, so in no case has the term intelligence anything to do with ‘insight learning’, as he has stated before. To give more expression to this fact of mismatch he would rather use the term ‘simulated intelligence’ (see also [9]). This conceptual strategy seems strange, since the term simulation [10] normally presupposes that there is a clear state of affairs, for which one defines a simplified ‘model’, by means of which the behavior of the original system can then be — simplified — viewed and examined in important respects. In the present case, however, it is not quite clear what the original system should be, which is to be simulated in the case of AI. There is so far no unified definition of ‘intelligence’ in the context of ‘AI’! As far as Hansch’s terminology itself is concerned, the terms ‘statistical-incremental learning’ as well as ‘insight learning’ are not clearly defined either; the relation to observable human behavior let alone to the postulated ‘equivalent brain structures’ is arbitrarily unclear (which is not improved by the relation to terms like ‘consciousness’ and ‘mind’ which are not defined yet).
[9] Severin Tatarczyk, Feb 19, 2023, on ‘Simulated Intelligence’: https://www.severint.net/2023/02/19/kompakt-warum-ich-den-begriff-simulierte-intelligenz-bevorzuge-und-warum-chatbots-so-menschlich-auf-uns-wirken/
[10] See the term ‘simulation’ in wkp-en: https://en.wikipedia.org/wiki/Simulation
[11] Doris Brelowski pointed me to the following article: James Bridle, 16.March 2023, „The stupidity of AI. Artificial intelligence in its current form is based on the wholesale appropriation of existing culture, and the notion that it is actually intelligent could be actively dangerous“, URL: https://www.theguardian.com/technology/2023/mar/16/the-stupidity-of-ai-artificial-intelligence-dall-e-chatgpt?CMP=Share_AndroidApp_Other . Comment: An article that knowledgeably and very sophisticatedly describes the interplay between forms of AI that are being ‘unleashed’ on the entire Internet by large corporations, and what this is doing to human culture and then, of course, to humans themselves. Two quotes from this very readable article: Quote 1: „The entirety of this kind of publicly available AI, whether it works with images or words, as well as the many data-driven applications like it, is based on this wholesale appropriation of existing culture, the scope of which we can barely comprehend. Public or private, legal or otherwise, most of the text and images scraped up by these systems exist in the nebulous domain of “fair use” (permitted in the US, but questionable if not outright illegal in the EU). Like most of what goes on inside advanced neural networks, it’s really impossible to understand how they work from the outside, rare encounters such as Lapine’s aside. But we can be certain of this: far from being the magical, novel creations of brilliant machines, the outputs of this kind of AI is entirely dependent on the uncredited and unremunerated work of generations of human artists.“ Quote 2: „Now, this didn’t happen because ChatGPT is inherently rightwing. It’s because it’s inherently stupid. It has read most of the internet, and it knows what human language is supposed to sound like, but it has no relation to reality whatsoever. It is dreaming sentences that sound about right, and listening to it talk is frankly about as interesting as listening to someone’s dreams. It is very good at producing what sounds like sense, and best of all at producing cliche and banality, which has composed the majority of its diet, but it remains incapable of relating meaningfully to the world as it actually is. Distrust anyone who pretends that this is an echo, even an approximation, of consciousness. (As this piece was going to publication, OpenAI released a new version of the system that powers ChatGPT, and said it was “less likely to make up facts”.)“
[12] David Krakauer in an Interview with Brian Gallagher in Nautilus, March 27, 2023, Does GPT-4 Really Understand What We’re Saying?, URL: https://nautil.us/does-gpt-4-really-understand-what-were-saying-291034/?_sp=d9a7861a-9644-44a7-8ba7-f95ee526d468.1680528060130. David Krakauer, an evolutionary theorist and president of the Santa Fe Institute for complexity science, analyzes the role of chat-GPT-4 models compared to the human language model and a more differentiated understanding of what ‘understanding’ and ‘Intelligence’ could mean. His main points of criticism are in close agreement with the position int he text above. He points out that (i) one has clearly to distinguish between the ‘information concept’ of Shannon and the concept of ‘meaning’. Something can represent a high information load but can nevertheless be empty of any meaning. Then he points out (ii) that there are several possible variants of the meaning of ‘understanding’. Coordinating with human understanding can work, but to understand in a constructive sense: no. Then Krakauer (iii) relates GPT-4 to the standard model of science which he characterizes as ‘parsimony’; chat-GPT-4 is clearly the opposite. Another point (iv) is the fact, that human experience has an ’emotional’ and a ‘physical’ aspect based on somato-sensory perceptions within its body. This is missing with GPT-4. This is somehow related (v) to the fact, that the human brain with its ‘algorithms’ is the product of millions of years of evolution in a complex environment. The GPT-4 algorithms have nothing comparable; they have only to ‘convince’ humans. Finally (vi) humans can generate ‘physical models’ inspired by their experience and can quickly argue by using such models. Thus Krakauer concludes “So the narrative that says we’ve rediscovered human reasoning is so misguided in so many ways. Just demonstrably false. That can’t be the way to go.”
[13] By Marie-José Kolly (text) and Merlin Flügel (illustration), 11.04.2023, “Chatbots like GPT can form wonderful sentences. That’s exactly what makes them a problem.” Artificial intelligence fools us into believing something that is not. A plea against the general enthusiasm. Online newspaper ‘Republik’ from Schweiz, URL: https://www.republik.ch/2023/04/11/chatbots-wie-gpt-koennen-wunderbare-saetze-bilden-genau-das-macht-sie-zum-problem? Here are some comments:
The text by Marie-José Kolly stands out because the algorithm named chatGPT(4) is characterized here both in its input-output behavior and additionally a comparison to humans is made at least to some extent.
The basic problem of the algorithm chatGPT(4) is (as also pointed out in my text above) that it has as input data exclusively text sets (also those of the users), which are analyzed according to purely statistical procedures in their formal properties. On the basis of the analyzed regularities, arbitrary text collages can then be generated, which are very similar in form to human texts, so much so that many people take them for ‘human-generated texts’. In fact, however, the algorithm lacks what we humans call ‘world knowledge’, it lacks real ‘thinking’, it lacks ‘own’ value positions, and the algorithm ‘does not understand’ its own text.
Due to this lack of its own reference to the world, the algorithm can be manipulated very easily via the available text volumes. A ‘mass production’ of ‘junk texts’, of ‘disinformation’ is thus very easily possible.
If one considers that modern democracies can only function if the majority of citizens have a common basis of facts that can be assumed to be ‘true’, a common body of knowledge, and reliable media, then the chatGPT(4) algorithm can massively destroy precisely these requirements for a democracy.
The interesting question then is whether chatGPT(4) can actually support a human society, especially a democratic society, in a positive-constructive way?
In any case, it is known that humans learn the use of their language from childhood on in direct contact with a real world, largely playfully, in interaction with other children/people. For humans ‘words’ are never isolated quantities, but they are always dynamically integrated into equally dynamic contexts. Language is never only ‘form’ but always at the same time ‘content’, and this in many different ways. This is only possible because humans have complex cognitive abilities, which include corresponding memory abilities as well as abilities for generalization.
The cultural-historical development from spoken language, via writing, books, libraries up to enormous digital data memories has indeed achieved tremendous things concerning the ‘forms’ of language and therein – possibly – encoded knowledge, but there is the impression that the ‘automation’ of the forms drives them into ‘isolation’, so that the forms lose more and more their contact to reality, to meaning, to truth. Language as a central moment of enabling more complex knowledge and more complex action is thus increasingly becoming a ‘parasite’ that claims more and more space and in the process destroys more and more meaning and truth.
[14] Gary Marcus, April 2023, Hoping for the Best as AI Evolves, Gary Marcus on the systems that “pose a real and imminent threat to the fabric of society.” Communications of the ACM, Volume 66, Issue 4, April 2023 pp 6–7, https://doi.org/10.1145/3583078 , Comment: Gary Marcus writes on the occasion of the effects of systems like chatGPT(OpenAI), Dalle-E2 and Lensa about the seriously increasing negative effects these tools can have within a society, to an extent that poses a serious threat to every society! These tools are inherently flawed in the areas of thinking, facts and hallucinations. At near zero cost, they can be used to create and execute large-scale disinformation campaigns very quickly. Looking to the globally important website ‘Stack Overflow’ for programmers as an example, one could (and can) see how the inflationary use of chatGPT due to its inherent many flaws pushes the Stack Overflow’s management team having to urge its users to completely stop using chatGPT in order to prevent the site’s collapse after 14 years. In the case of big players who specifically target disinformation, such a measure is ineffective. These players aim to create a data world in which no one will be able to trust anyone. With this in mind, Gary Marcus sets out 4 postulates that every society should implement: (1) Automatically generated not certified content should be completely banned; (2) Legally effective measures must be adopted that can prevent ‘misinformation’; (3) User accounts must be made tamper-proof; (4) A new generation of AI tools is needed that can verify facts. (Translated with partial support from www.DeepL.com/Translator (free version))
The whole text shows a dynamic, which induces many changes. Difficult to plan ‘in advance’.
Perhaps, some time, it will look like a ‘book’, at least ‘for a moment’.
I have started a ‘book project’ in parallel. This was motivated by the need to provide potential users of our new oksimo.R software with a coherent explanation of how the oksimo.R software, when used, generates an empirical theory in the format of a screenplay. The primary source of the book is in German and will be translated step by step here in the uffmm.blog.
INTRODUCTION
In a rather foundational paper about an idea, how one can generalize ‘systems engineering’ [*1] to the art of ‘theory engineering’ [1] a new conceptual framework has been outlined for a ‘sustainable applied empirical theory (SAET)’. Part of this new framework has been the idea that the classical recourse to groups of special experts (mostly ‘engineers’ in engineering) is too restrictive in the light of the new requirement of being sustainable: sustainability is primarily based on ‘diversity’ combined with the ‘ability to predict’ from this diversity probable future states which keep life alive. The aspect of diversity induces the challenge to see every citizen as a ‘natural expert’, because nobody can know in advance and from some non-existing absolut point of truth, which knowledge is really important. History shows that the ‘mainstream’ is usually to a large degree ‘biased’ [*1b].
With this assumption, that every citizen is a ‘natural expert’, science turns into a ‘general science’ where all citizens are ‘natural members’ of science. I will call this more general concept of science ‘sustainable citizen science (SCS)’ or ‘Citizen Science 2.0 (CS2)’. The important point here is that a sustainable citizen science is not necessarily an ‘arbitrary’ process. While the requirement of ‘diversity’ relates to possible contents, to possible ideas, to possible experiments, and the like, it follows from the other requirement of ‘predictability’/ of being able to make some useful ‘forecasts’, that the given knowledge has to be in a format, which allows in a transparent way the construction of some consequences, which ‘derive’ from the ‘given’ knowledge and enable some ‘new’ knowledge. This ability of forecasting has often been understood as the business of ‘logic’ providing an ‘inference concept’ given by ‘rules of deduction’ and a ‘practical pattern (on the meta level)’, which defines how these rules have to be applied to satisfy the inference concept. But, looking to real life, to everyday life or to modern engineering and economy, one can learn that ‘forecasting’ is a complex process including much more than only cognitive structures nicely fitting into some formulas. For this more realistic forecasting concept we will use here the wording ‘common logic’ and for the cognitive adventure where common logic is applied we will use the wording ‘common science’. ‘Common science’ is structurally not different from ‘usual science’, but it has a substantial wider scope and is using the whole of mankind as ‘experts’.
The following chapters/ sections try to illustrate this common science view by visiting different special views which all are only ‘parts of a whole’, a whole which we can ‘feel’ in every moment, but which we can not yet completely grasp with our theoretical concepts.
CONTENT
Language (Main message: “The ordinary language is the ‘meta language’ to every special language. This can be used as a ‘hint’ to something really great: the mystery of the ‘self-creating’ power of the ordinary language which for most people is unknown although it happens every moment.”)
Concrete Abstract Statements (Main message: “… you will probably detect, that nearly all words of a language are ‘abstract words’ activating ‘abstract meanings’. …If you cannot provide … ‘concrete situations’ the intended meaning of your abstract words will stay ‘unclear’: they can mean ‘nothing or all’, depending from the decoding of the hearer.”)
True False Undefined (Main message: “… it reveals that ’empirical (observational) evidence’ is not necessarily an automatism: it presupposes appropriate meaning spaces embedded in sets of preferences, which are ‘observation friendly’.“
Beyond Now (Main message: “With the aid of … sequences revealing possible changes the NOW is turned into a ‘moment’ embedded in a ‘process’, which is becoming the more important reality. The NOW is something, but the PROCESS is more.“)
Playing with the Future (Main message: “In this sense seems ‘language’ to be the master tool for every brain to mediate its dynamic meaning structures with symbolic fix points (= words, expressions) which as such do not change, but the meaning is ‘free to change’ in any direction. And this ‘built in ‘dynamics’ represents an ‘internal potential’ for uncountable many possible states, which could perhaps become ‘true’ in some ‘future state’. Thus ‘future’ can begin in these potentials, and thinking is the ‘playground’ for possible futures.(but see [18])”)
Forecasting – Prediction: What? (This chapter explains the cognitive machinery behind forecasting/ predictions, how groups of human actors can elaborate shared descriptions, and how it is possible to start with sequences of singularities to built up a growing picture of the empirical world which appears as a radical infinite and indeterministic space. )
!!! From here all the following chapters have to be re-written !!!
Boolean Logic (Explains what boolean logic is, how it enables the working of programmable machines, but that it is of nearly no help for the ‘heart’ of forecasting.)
/* Often people argue against the usage of the wikipedia encyclopedia as not ‘scientific’ because the ‘content’ of an entry in this encyclopedia can ‘change’. This presupposes the ‘classical view’ of scientific texts to be ‘stable’, which presupposes further, that such a ‘stable text’ describes some ‘stable subject matter’. But this view of ‘steadiness’ as the major property of ‘true descriptions’ is in no correspondence with real scientific texts! The reality of empirical science — even as in some special disciplines like ‘physics’ — is ‘change’. Looking to Aristotle’s view of nature, to Galileo Galilei, to Newton, to Einstein and many others, you will not find a ‘single steady picture’ of nature and science, and physics is only a very simple strand of science compared to the live-sciences and many others. Thus wikipedia is a real scientific encyclopedia give you the breath of world knowledge with all its strengths and limits at once. For another, more general argument, see In Favour for Wikipedia */
[*1] Meaning operator ‘…’ : In this text (and in nearly all other texts of this author) the ‘inverted comma’ is used quite heavily. In everyday language this is not common. In some special languages (theory of formal languages or in programming languages or in meta-logic) the inverted comma is used in some special way. In this text, which is primarily a philosophical text, the inverted comma sign is used as a ‘meta-language operator’ to raise the intention of the reader to be aware, that the ‘meaning’ of the word enclosed in the inverted commas is ‘text specific’: in everyday language usage the speaker uses a word and assumes tacitly that his ‘intended meaning’ will be understood by the hearer of his utterance as ‘it is’. And the speaker will adhere to his assumption until some hearer signals, that her understanding is different. That such a difference is signaled is quite normal, because the ‘meaning’ which is associated with a language expression can be diverse, and a decision, which one of these multiple possible meanings is the ‘intended one’ in a certain context is often a bit ‘arbitrary’. Thus, it can be — but must not — a meta-language strategy, to comment to the hearer (or here: the reader), that a certain expression in a communication is ‘intended’ with a special meaning which perhaps is not the commonly assumed one. Nevertheless, because the ‘common meaning’ is no ‘clear and sharp subject’, a ‘meaning operator’ with the inverted commas has also not a very sharp meaning. But in the ‘game of language’ it is more than nothing 🙂
[*1b] That the main stream ‘is biased’ is not an accident, not a ‘strange state’, not a ‘failure’, it is the ‘normal state’ based on the deeper structure how human actors are ‘built’ and ‘genetically’ and ‘cultural’ ‘programmed’. Thus the challenge to ‘survive’ as part of the ‘whole biosphere’ is not a ‘partial task’ to solve a single problem, but to solve in some sense the problem how to ‘shape the whole biosphere’ in a way, which enables a live in the universe for the time beyond that point where the sun is turning into a ‘red giant’ whereby life will be impossible on the planet earth (some billion years ahead)[22]. A remarkable text supporting this ‘complex view of sustainability’ can be found in Clark and Harvey, summarized at the end of the text. [23]
[*2] The meaning of the expression ‘normal’ is comparable to a wicked problem. In a certain sense we act in our everyday world ‘as if there exists some standard’ for what is assumed to be ‘normal’. Look for instance to houses, buildings: to a certain degree parts of a house have a ‘standard format’ assuming ‘normal people’. The whole traffic system, most parts of our ‘daily life’ are following certain ‘standards’ making ‘planning’ possible. But there exists a certain percentage of human persons which are ‘different’ compared to these introduced standards. We say that they have a ‘handicap’ compared to this assumed ‘standard’, but this so-called ‘standard’ is neither 100% true nor is the ‘given real world’ in its properties a ‘100% subject’. We have learned that ‘properties of the real world’ are distributed in a rather ‘statistical manner’ with different probabilities of occurrences. To ‘find our way’ in these varying occurrences we try to ‘mark’ the main occurrences as ‘normal’ to enable a basic structure for expectations and planning. Thus, if in this text the expression ‘normal’ is used it refers to the ‘most common occurrences’.
[*3] Thus we have here a ‘threefold structure’ embracing ‘perception events, memory events, and expression events’. Perception events represent ‘concrete events’; memory events represent all kinds of abstract events but they all have a ‘handle’ which maps to subsets of concrete events; expression events are parts of an abstract language system, which as such is dynamically mapped onto the abstract events. The main source for our knowledge about perceptions, memory and expressions is experimental psychology enhanced by many other disciplines.
[*4] Characterizing language expressions by meaning – the fate of any grammar: the sentence ” … ‘words’ (= expressions) of a language which can activate such abstract meanings are understood as ‘abstract words’, ‘general words’, ‘category words’ or the like.” is pointing to a deep property of every ordinary language, which represents the real power of language but at the same time the great weakness too: expressions as such have no meaning. Hundreds, thousands, millions of words arranged in ‘texts’, ‘documents’ can show some statistical patterns’ and as such these patterns can give some hint which expressions occur ‘how often’ and in ‘which combinations’, but they never can give a clue to the associated meaning(s). During more than three-thousand years humans have tried to describe ordinary language in a more systematic way called ‘grammar’. Due to this radically gap between ‘expressions’ as ‘observable empirical facts’ and ‘meaning constructs’ hidden inside the brain it was all the time a difficult job to ‘classify’ expressions as representing a certain ‘type’ of expression like ‘nouns’, ‘predicates’, ‘adjectives’, ‘defining article’ and the like. Without regressing to the assumed associated meaning such a classification is not possible. On account of the fuzziness of every meaning ‘sharp definitions’ of such ‘word classes’ was never and is not yet possible. One of the last big — perhaps the biggest ever — project of a complete systematic grammar of a language was the grammar project of the ‘Akademie der Wissenschaften der DDR’ (‘Academy of Sciences of the GDR’) from 1981 with the title “Grundzüge einer Deutschen Grammatik” (“Basic features of a German grammar”). A huge team of scientists worked together using many modern methods. But in the preface you can read, that many important properties of the language are still not sufficiently well describable and explainable. See: Karl Erich Heidolph, Walter Flämig, Wolfgang Motsch et al.: Grundzüge einer deutschen Grammatik. Akademie, Berlin 1981, 1028 Seiten.
[*5] Differing opinions about a given situation manifested in uttered expressions are a very common phenomenon in everyday communication. In some sense this is ‘natural’, can happen, and it should be no substantial problem to ‘solve the riddle of being different’. But as you can experience, the ability of people to solve the occurrence of different opinions is often quite weak. Culture is suffering by this as a whole.
[1] Gerd Doeben-Henisch, 2022, From SYSTEMS Engineering to THEORYEngineering, see: https://www.uffmm.org/2022/05/26/from-systems-engineering-to-theory-engineering/(Remark: At the time of citation this post was not yet finished, because there are other posts ‘corresponding’ with that post, which are too not finished. Knowledge is a dynamic network of interwoven views …).
[1d] ‘usual science’ is the game of science without having a sustainable format like in citizen science 2.0.
[2] Science, see e.g. wkp-en: https://en.wikipedia.org/wiki/Science
Citation = “In modern science, the term “theory” refers to scientific theories, a well-confirmed type of explanation of nature, made in a way consistent with the scientific method, and fulfilling the criteria required by modern science. Such theories are described in such a way that scientific tests should be able to provide empirical support for it, or empirical contradiction (“falsify“) of it. Scientific theories are the most reliable, rigorous, and comprehensive form of scientific knowledge,[1] in contrast to more common uses of the word “theory” that imply that something is unproven or speculative (which in formal terms is better characterized by the word hypothesis).[2] Scientific theories are distinguished from hypotheses, which are individual empirically testableconjectures, and from scientific laws, which are descriptive accounts of the way nature behaves under certain conditions.”
[2b] History of science in wkp-en: https://en.wikipedia.org/wiki/History_of_science#Scientific_Revolution_and_birth_of_New_Science
[3] Theory, see wkp-en: https://en.wikipedia.org/wiki/Theory#:~:text=A%20theory%20is%20a%20rational,or%20no%20discipline%20at%20all.
Citation = “A theory is a rational type of abstract thinking about a phenomenon, or the results of such thinking. The process of contemplative and rational thinking is often associated with such processes as observational study or research. Theories may be scientific, belong to a non-scientific discipline, or no discipline at all. Depending on the context, a theory’s assertions might, for example, include generalized explanations of how nature works. The word has its roots in ancient Greek, but in modern use it has taken on several related meanings.”
Citation = “In modern science, the term “theory” refers to scientific theories, a well-confirmed type of explanation of nature, made in a way consistent with the scientific method, and fulfilling the criteria required by modern science. Such theories are described in such a way that scientific tests should be able to provide empirical support for it, or empirical contradiction (“falsify“) of it. Scientific theories are the most reliable, rigorous, and comprehensive form of scientific knowledge,[1] in contrast to more common uses of the word “theory” that imply that something is unproven or speculative (which in formal terms is better characterized by the word hypothesis).[2] Scientific theories are distinguished from hypotheses, which are individual empirically testableconjectures, and from scientific laws, which are descriptive accounts of the way nature behaves under certain conditions.”
[4b] Empiricism in wkp-en: https://en.wikipedia.org/wiki/Empiricism
[4c] Scientific method in wkp-en: https://en.wikipedia.org/wiki/Scientific_method
Citation =”The scientific method is an empirical method of acquiring knowledge that has characterized the development of science since at least the 17th century (with notable practitioners in previous centuries). It involves careful observation, applying rigorous skepticism about what is observed, given that cognitive assumptions can distort how one interprets the observation. It involves formulating hypotheses, via induction, based on such observations; experimental and measurement-based statistical testing of deductions drawn from the hypotheses; and refinement (or elimination) of the hypotheses based on the experimental findings. These are principles of the scientific method, as distinguished from a definitive series of steps applicable to all scientific enterprises.[1][2][3] [4c]
and
Citation = “The purpose of an experiment is to determine whether observations[A][a][b] agree with or conflict with the expectations deduced from a hypothesis.[6]: Book I, [6.54] pp.372, 408 [b] Experiments can take place anywhere from a garage to a remote mountaintop to CERN’s Large Hadron Collider. There are difficulties in a formulaic statement of method, however. Though the scientific method is often presented as a fixed sequence of steps, it represents rather a set of general principles.[7] Not all steps take place in every scientific inquiry (nor to the same degree), and they are not always in the same order.[8][9]”
[5] Gerd Doeben-Henisch, “Is Mathematics a Fake? No! Discussing N.Bourbaki, Theory of Sets (1968) – Introduction”, 2022, https://www.uffmm.org/2022/06/06/n-bourbaki-theory-of-sets-1968-introduction/
[6] Logic, see wkp-en: https://en.wikipedia.org/wiki/Logic
[7] W. C. Kneale, The Development of Logic, Oxford University Press (1962)
[8] Set theory, in wkp-en: https://en.wikipedia.org/wiki/Set_theory
[9] N.Bourbaki, Theory of Sets , 1968, with a chapter about structures, see: https://en.wikipedia.org/wiki/%C3%89l%C3%A9ments_de_math%C3%A9matique
[10] = [5]
[11] Ludwig Josef Johann Wittgenstein ( 1889 – 1951): https://en.wikipedia.org/wiki/Ludwig_Wittgenstein
[12] Ludwig Wittgenstein, 1953: Philosophische Untersuchungen [PU], 1953: Philosophical Investigations [PI], translated by G. E. M. Anscombe /* For more details see: https://en.wikipedia.org/wiki/Philosophical_Investigations */
[13] Wikipedia EN, Speech acts: https://en.wikipedia.org/wiki/Speech_act
[14] While the world view constructed in a brain is ‘virtual’ compared to the ‘real word’ outside the brain (where the body outside the brain is also functioning as ‘real world’ in relation to the brain), does the ‘virtual world’ in the brain function for the brain mostly ‘as if it is the real world’. Only under certain conditions can the brain realize a ‘difference’ between the triggering outside real world and the ‘virtual substitute for the real world’: You want to use your bicycle ‘as usual’ and then suddenly you have to notice that it is not at that place where is ‘should be’. …
[15] Propositional Calculus, see wkp-en: https://en.wikipedia.org/wiki/Propositional_calculus#:~:text=Propositional%20calculus%20is%20a%20branch,of%20arguments%20based%20on%20them.
[16] Boolean algebra, see wkp-en: https://en.wikipedia.org/wiki/Boolean_algebra
[17] Boolean (or propositional) Logic: As one can see in the mentioned articles of the English wikipedia, the term ‘boolean logic’ is not common. The more logic-oriented authors prefer the term ‘boolean calculus’ [15] and the more math-oriented authors prefer the term ‘boolean algebra’ [16]. In the view of this author the general view is that of ‘language use’ with ‘logic inference’ as leading idea. Therefore the main topic is ‘logic’, in the case of propositional logic reduced to a simple calculus whose similarity with ‘normal language’ is widely ‘reduced’ to a play with abstract names and operators. Recommended: the historical comments in [15].
[18] Clearly, thinking alone can not necessarily induce a possible state which along the time line will become a ‘real state’. There are numerous factors ‘outside’ the individual thinking which are ‘driving forces’ to push real states to change. But thinking can in principle synchronize with other individual thinking and — in some cases — can get a ‘grip’ on real factors causing real changes.
[19] This kind of knowledge is not delivered by brain science alone but primarily from experimental (cognitive) psychology which examines observable behavior and ‘interprets’ this behavior with functional models within an empirical theory.
[20] Predicate Logic or First-Order Logic or … see: wkp-en: https://en.wikipedia.org/wiki/First-order_logic#:~:text=First%2Dorder%20logic%E2%80%94also%20known,%2C%20linguistics%2C%20and%20computer%20science.
[21] Gerd Doeben-Henisch, In Favour of Wikipedia, https://www.uffmm.org/2022/07/31/in-favour-of-wikipedia/, 31 July 2022
[22] The sun, see wkp-ed https://en.wikipedia.org/wiki/Sun (accessed 8 Aug 2022)
[23] By Clark, William C., and Alicia G. Harley – https://doi.org/10.1146/annurev-environ-012420-043621, Clark, William C., and Alicia G. Harley. 2020. “Sustainability Science: Toward a Synthesis.” Annual Review of Environment and Resources 45 (1): 331–86, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=109026069
[24] Sustainability in wkp-en: https://en.wikipedia.org/wiki/Sustainability#Dimensions_of_sustainability
[27] SDG 4 in wkp-en: https://en.wikipedia.org/wiki/Sustainable_Development_Goal_4
[28] Thomas Rid, Rise of the Machines. A Cybernetic History, W.W.Norton & Company, 2016, New York – London
[29] Doeben-Henisch, G., 2006, Reducing Negative Complexity by a Semiotic System In: Gudwin, R., & Queiroz, J., (Eds). Semiotics and Intelligent Systems Development. Hershey et al: Idea Group Publishing, 2006, pp.330-342
[30] Döben-Henisch, G., Reinforcing the global heartbeat: Introducing the planet earth simulator project, In M. Faßler & C. Terkowsky (Eds.), URBAN FICTIONS. Die Zukunft des Städtischen. München, Germany: Wilhelm Fink Verlag, 2006, pp.251-263
[29] The idea that individual disciplines are not good enough for the ‘whole of knowledge’ is expressed in a clear way in a video of the theoretical physicist and philosopher Carlo Rovell: Carlo Rovelli on physics and philosophy, June 1, 2022, Video from the Perimeter Institute for Theoretical Physics. Theoretical physicist, philosopher, and international bestselling author Carlo Rovelli joins Lauren and Colin for a conversation about the quest for quantum gravity, the importance of unlearning outdated ideas, and a very unique way to get out of a speeding ticket.
[] By Azote for Stockholm Resilience Centre, Stockholm University – https://www.stockholmresilience.org/research/research-news/2016-06-14-how-food-connects-all-the-sdgs.html, CC BY 4.0, https://commons.wikimedia.org/w/index.php?curid=112497386
[] Sierra Club in wkp-en: https://en.wikipedia.org/wiki/Sierra_Club
[] Herbert Bruderer, Where is the Cradle of the Computer?, June 20, 2022, URL: https://cacm.acm.org/blogs/blog-cacm/262034-where-is-the-cradle-of-the-computer/fulltext (accessed: July 20, 2022)
[] UN. Secretary-General; World Commission on Environment and Development, 1987, Report of the World Commission on Environment and Development : note / by the Secretary-General., https://digitallibrary.un.org/record/139811 (accessed: July 20, 2022) (A more readable format: https://sustainabledevelopment.un.org/content/documents/5987our-common-future.pdf )
/* Comment: Gro Harlem Brundtland (Norway) has been the main coordinator of this document */
[] Chaudhuri, S.,et al.Neurosymbolic programming. Foundations and Trends in Programming Languages 7, 158-243 (2021).
[] Nello Cristianini, Teresa Scantamburlo, James Ladyman, The social turn of artificial intelligence, in: AI & SOCIETY, https://doi.org/10.1007/s00146-021-01289-8
[] Carl DiSalvo, Phoebe Sengers, and Hrönn Brynjarsdóttir, Mapping the landscape of sustainable hci, In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’10, page 1975–1984, New York, NY, USA, 2010. Association for Computing Machinery.
[] Claude Draude, Christian Gruhl, Gerrit Hornung, Jonathan Kropf, Jörn Lamla, Jan Marco Leimeister, Bernhard Sick, Gerd Stumme, Social Machines, in: Informatik Spektrum, https://doi.org/10.1007/s00287-021-01421-4
[] EU: High-Level Expert Group on AI (AI HLEG), A definition of AI: Main capabilities and scientific disciplines, European Commission communications published on 25 April 2018 (COM(2018) 237 final), 7 December 2018 (COM(2018) 795 final) and 8 April 2019 (COM(2019) 168 final). For our definition of Artificial Intelligence (AI), please refer to our document published on 8 April 2019: https://ec.europa.eu/newsroom/dae/document.cfm?doc_id=56341
[] EU: High-Level Expert Group on AI (AI HLEG), Policy and investment recommendations for trustworthy Artificial Intelligence, 2019, https://digital-strategy.ec.europa.eu/en/library/policy-and-investment-recommendations-trustworthy-artificial-intelligence
[] European Union. Regulation 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC General Data Protection Regulation; http://eur-lex.europa.eu/eli/reg/2016/679/oj (Wirksam ab 25.Mai 2018) [26.2.2022]
[] C.S. Holling. Resilience and stability of ecological systems. Annual Review of Ecology and Systematics, 4(1):1–23, 1973
[] John P. van Gigch. 1991. System Design Modeling and Metamodeling. Springer US. DOI:https://doi.org/10.1007/978-1-4899-0676-2
[] Gudwin, R.R. (2003), On a Computational Model of the Peircean Semiosis, IEEE KIMAS 2003 Proceedings
[] J.A. Jacko and A. Sears, Eds., The Human-Computer Interaction Handbook. Fundamentals, Evolving Technologies, and emerging Applications. 1st edition, 2003.
[] LeCun, Y., Bengio, Y., & Hinton, G. Deep learning. Nature 521, 436-444 (2015).
[] Lenat, D. What AI can learn from Romeo & Juliet.Forbes (2019)
[] Pierre Lévy, Collective Intelligence. mankind’s emerging world in cyberspace, Perseus books, Cambridge (M A), 1997 (translated from the French Edition 1994 by Robert Bonnono)
[] Lexikon der Nachhaltigkeit, ‘Starke Nachhaltigkeit‘, https://www.nachhaltigkeit.info/artikel/schwache_vs_starke_nachhaltigkeit_1687.htm (acessed: July 21, 2022)
[] Michael L. Littman, Ifeoma Ajunwa, Guy Berger, Craig Boutilier, Morgan Currie, Finale Doshi-Velez, Gillian Hadfield, Michael C. Horowitz, Charles Isbell, Hiroaki Kitano, Karen Levy, Terah Lyons, Melanie Mitchell, Julie Shah, Steven Sloman, Shannon Vallor, and Toby Walsh. “Gathering Strength, Gathering Storms: The One Hundred Year Study on Artificial Intelligence (AI100) 2021 Study Panel Report.” Stanford University, Stanford, CA, September 2021. Doc: http://ai100.stanford.edu/2021-report.
[] Kathryn Merrick. Value systems for developmental cognitive robotics: A survey. Cognitive Systems Research, 41:38 – 55, 2017
[] Illah Reza Nourbakhsh and Jennifer Keating, AI and Humanity, MIT Press, 2020 /* An examination of the implications for society of rapidly advancing artificial intelligence systems, combining a humanities perspective with technical analysis; includes exercises and discussion questions. */
[] Olazaran, M. , A sociological history of the neural network controversy. Advances in Computers37, 335-425 (1993).
[] Friedrich August Hayek (1945), The use of knowledge in society. The American Economic Review 35, 4 (1945), 519–530
[] Karl Popper, „A World of Propensities“, in: Karl Popper, „A World of Propensities“, Thoemmes Press, Bristol, (Vortrag 1988, leicht erweitert neu abgedruckt 1990, repr. 1995)
[] Karl Popper, „Towards an Evolutionary Theory of Knowledge“, in: Karl Popper, „A World of Propensities“, Thoemmes Press, Bristol, (Vortrag 1989, ab gedruckt in 1990, repr. 1995)
[] Karl Popper, „All Life is Problem Solving“, Artikel, ursprünglich ein Vortrag 1991 auf Deutsch, erstmalig publiziert in dem Buch (auf Deutsch) „Alles Leben ist Problemlösen“ (1994), dann in dem Buch (auf Englisch) „All Life is Problem Solving“, 1999, Routledge, Taylor & Francis Group, London – New York
[] A. Sears and J.A. Jacko, Eds., The Human-Computer Interaction Handbook. Fundamentals, Evolving Technologies, and emerging Applications. 2nd edition, 2008.
[] Skaburskis, Andrejs (19 December 2008). “The origin of “wicked problems””. Planning Theory & Practice. 9 (2): 277-280. doi:10.1080/14649350802041654. At the end of Rittel’s presentation, West Churchman responded with that pensive but expressive movement of voice that some may well remember, ‘Hmm, those sound like “wicked problems.”‘
[] Thoppilan, R., et al. LaMDA: Language models for dialog applications. arXiv 2201.08239 (2022).
[] Wurm, Daniel; Zielinski, Oliver; Lübben, Neeske; Jansen, Maike; Ramesohl, Stephan (2021) : Wege in eine ökologische Machine Economy: Wir brauchen eine ‘Grüne Governance der Machine Economy’, um das Zusammenspiel von Internet of Things, Künstlicher Intelligenz und Distributed Ledger Technology ökologisch zu gestalten, Wuppertal Report, No. 22, Wuppertal Institut für Klima, Umwelt, Energie, Wuppertal, https://doi.org/10.48506/opus-7828
[] Aimee van Wynsberghe, Sustainable AI: AI for sustainability and the sustainability of AI, in: AI and Ethics (2021) 1:213–218, see: https://doi.org/10.1007/s43681
[] R. I. Damper (2000), Editorial for the special issue on ‘Emergent Properties of Complex Systems’: Emergence and levels of abstraction. International Journal of Systems Science 31, 7 (2000), 811–818. DOI:https://doi.org/10.1080/002077200406543
[] Gerd Doeben-Henisch (2004), The Planet Earth Simulator Project – A Case Study in Computational Semiotics, IEEE AFRICON 2004, pp.417 – 422
[] Eric Bonabeau (2009), Decisions 2.0: The power of collective intelligence. MIT Sloan Management Review 50, 2 (Winter 2009), 45-52.
[] Jim Giles (2005), Internet encyclopaedias go head to head. Nature 438, 7070 (Dec. 2005), 900–901. DOI:https://doi.org/10.1038/438900a
[] T. Bosse, C. M. Jonker, M. C. Schut, and J. Treur (2006), Collective representational content for shared extended mind. Cognitive Systems Research 7, 2-3 (2006), pp.151-174, DOI:https://doi.org/10.1016/j.cogsys.2005.11.007
[] Romina Cachia, Ramón Compañó, and Olivier Da Costa (2007), Grasping the potential of online social networks for foresight. Technological Forecasting and Social Change 74, 8 (2007), oo.1179-1203. DOI:https://doi.org/10.1016/j.techfore.2007.05.006
[] Tom Gruber (2008), Collective knowledge systems: Where the social web meets the semantic web. Web Semantics: Science, Services and Agents on the World Wide Web 6, 1 (2008), 4–13. DOI:https://doi.org/10.1016/j.websem.2007.11.011
[] Luca Iandoli, Mark Klein, and Giuseppe Zollo (2009), Enabling on-line deliberation and collective decision-making through large-scale argumentation. International Journal of Decision Support System Technology 1, 1 (Jan. 2009), 69–92. DOI:https://doi.org/10.4018/jdsst.2009010105
[] Shuangling Luo, Haoxiang Xia, Taketoshi Yoshida, and Zhongtuo Wang (2009), Toward collective intelligence of online communities: A primitive conceptual model. Journal of Systems Science and Systems Engineering 18, 2 (01 June 2009), 203–221. DOI:https://doi.org/10.1007/s11518-009-5095-0
[] Dawn G. Gregg (2010), Designing for collective intelligence. Communications of the ACM 53, 4 (April 2010), 134–138. DOI:https://doi.org/10.1145/1721654.1721691
[] Rolf Pfeifer, Jan Henrik Sieg, Thierry Bücheler, and Rudolf Marcel Füchslin. 2010. Crowdsourcing, open innovation and collective intelligence in the scientific method: A research agenda and operational framework. (2010). DOI:https://doi.org/10.21256/zhaw-4094
[] Martijn C. Schut. 2010. On model design for simulation of collective intelligence. Information Sciences 180, 1 (2010), 132–155. DOI:https://doi.org/10.1016/j.ins.2009.08.006 Special Issue on Collective Intelligence
[] Dimitrios J. Vergados, Ioanna Lykourentzou, and Epaminondas Kapetanios (2010), A resource allocation framework for collective intelligence system engineering. In Proceedings of the International Conference on Management of Emergent Digital EcoSystems (MEDES’10). ACM, New York, NY, 182–188. DOI:https://doi.org/10.1145/1936254.1936285
[] Anita Williams Woolley, Christopher F. Chabris, Alex Pentland, Nada Hashmi, and Thomas W. Malone (2010), Evidence for a collective intelligence factor in the performance of human groups. Science 330, 6004 (2010), 686–688. DOI:https://doi.org/10.1126/science.1193147
[] Michael A. Woodley and Edward Bell (2011), Is collective intelligence (mostly) the General Factor of Personality? A comment on Woolley, Chabris, Pentland, Hashmi and Malone (2010). Intelligence 39, 2 (2011), 79–81. DOI:https://doi.org/10.1016/j.intell.2011.01.004
[] Joshua Introne, Robert Laubacher, Gary Olson, and Thomas Malone (2011), The climate CoLab: Large scale model-based collaborative planning. In Proceedings of the 2011 International Conference on Collaboration Technologies and Systems (CTS’11). 40–47. DOI:https://doi.org/10.1109/CTS.2011.5928663
[] Miguel de Castro Neto and Ana Espírtio Santo (2012), Emerging collective intelligence business models. In MCIS 2012 Proceedings. Mediterranean Conference on Information Systems. https://aisel.aisnet.org/mcis2012/14
[] Peng Liu, Zhizhong Li (2012), Task complexity: A review and conceptualization framework, International Journal of Industrial Ergonomics 42 (2012), pp. 553 – 568
[] Sean Wise, Robert A. Paton, and Thomas Gegenhuber. (2012), Value co-creation through collective intelligence in the public sector: A review of US and European initiatives. VINE 42, 2 (2012), 251–276. DOI:https://doi.org/10.1108/03055721211227273
[] Antonietta Grasso and Gregorio Convertino (2012), Collective intelligence in organizations: Tools and studies. Computer Supported Cooperative Work (CSCW) 21, 4 (01 Oct 2012), 357–369. DOI:https://doi.org/10.1007/s10606-012-9165-3
[] Sandro Georgi and Reinhard Jung (2012), Collective intelligence model: How to describe collective intelligence. In Advances in Intelligent and Soft Computing. Vol. 113. Springer, 53–64. DOI:https://doi.org/10.1007/978-3-642-25321-8_5
[] H. Santos, L. Ayres, C. Caminha, and V. Furtado (2012), Open government and citizen participation in law enforcement via crowd mapping. IEEE Intelligent Systems 27 (2012), 63–69. DOI:https://doi.org/10.1109/MIS.2012.80
[] Jörg Schatzmann & René Schäfer & Frederik Eichelbaum (2013), Foresight 2.0 – Definition, overview & evaluation, Eur J Futures Res (2013) 1:15 DOI 10.1007/s40309-013-0015-4
[] Sylvia Ann Hewlett, Melinda Marshall, and Laura Sherbin (2013), How diversity can drive innovation. Harvard Business Review 91, 12 (2013), 30–30
[] Tony Diggle (2013), Water: How collective intelligence initiatives can address this challenge. Foresight 15, 5 (2013), 342–353. DOI:https://doi.org/10.1108/FS-05-2012-0032
[] Hélène Landemore and Jon Elster. 2012. Collective Wisdom: Principles and Mechanisms. Cambridge University Press. DOI:https://doi.org/10.1017/CBO9780511846427
[] Jerome C. Glenn (2013), Collective intelligence and an application by the millennium project. World Futures Review 5, 3 (2013), 235–243. DOI:https://doi.org/10.1177/1946756713497331
[] Detlef Schoder, Peter A. Gloor, and Panagiotis Takis Metaxas (2013), Social media and collective intelligence—Ongoing and future research streams. KI – Künstliche Intelligenz 27, 1 (1 Feb. 2013), 9–15. DOI:https://doi.org/10.1007/s13218-012-0228-x
[] V. Singh, G. Singh, and S. Pande (2013), Emergence, self-organization and collective intelligence—Modeling the dynamics of complex collectives in social and organizational settings. In 2013 UKSim 15th International Conference on Computer Modelling and Simulation. 182–189. DOI:https://doi.org/10.1109/UKSim.2013.77
[] A. Kornrumpf and U. Baumöl (2014), A design science approach to collective intelligence systems. In 2014 47th Hawaii International Conference on System Sciences. 361–370. DOI:https://doi.org/10.1109/HICSS.2014.53
[] Michael A. Peters and Richard Heraud. 2015. Toward a political theory of social innovation: Collective intelligence and the co-creation of social goods. 3, 3 (2015), 7–23. https://researchcommons.waikato.ac.nz/handle/10289/9569
[] Juho Salminen. 2015. The Role of Collective Intelligence in Crowdsourcing Innovation. PhD dissertation. Lappeenranta University of Technology
[] Aelita Skarzauskiene and Monika Maciuliene (2015), Modelling the index of collective intelligence in online community projects. In International Conference on Cyber Warfare and Security. Academic Conferences International Limited, 313
[] AYA H. KIMURA and ABBY KINCHY (2016), Citizen Science: Probing the Virtues and Contexts of Participatory Research, Engaging Science, Technology, and Society 2 (2016), 331-361, DOI:10.17351/ests2016.099
[] Philip Tetlow, Dinesh Garg, Leigh Chase, Mark Mattingley-Scott, Nicholas Bronn, Kugendran Naidoo†, Emil Reinert (2022), Towards a Semantic Information Theory (Introducing Quantum Corollas), arXiv:2201.05478v1 [cs.IT] 14 Jan 2022, 28 pages
[] Melanie Mitchell, What Does It Mean to Align AI With Human Values?, quanta magazin, Quantized Columns, 19.Devember 2022, https://www.quantamagazine.org/what-does-it-mean-to-align-ai-with-human-values-20221213#
Comment by Gerd Doeben-Henisch:
[] Nick Bostrom. Superintelligence. Paths, Dangers, Strategies. Oxford University Press, Oxford (UK), 1 edition, 2014.
[] Scott Aaronson, Reform AI Alignment, Update: 22.November 2022, https://scottaaronson.blog/?p=6821
[] Andrew Y. Ng, Stuart J. Russell, Algorithms for Inverse Reinforcement Learning, ICML 2000: Proceedings of the Seventeenth International Conference on Machine LearningJune 2000 Pages 663–670
[] Pat Langley (ed.), ICML ’00: Proceedings of the Seventeenth International Conference on Machine Learning, Morgan Kaufmann Publishers Inc., 340 Pine Street, Sixth Floor, San Francisco, CA, United States, Conference 29 June 2000- 2 July 2000, 29.June 2000
Abstract: Extrapolating Beyond Suboptimal Demonstrations via Inverse Reinforcement Learning from Observations Daniel S. Brown * 1 Wonjoon Goo * 1 Prabhat Nagarajan 2 Scott Niekum 1 You can read in the abstract: “A critical flaw of existing inverse reinforcement learning (IRL) methods is their inability to significantly outperform the demonstrator. This is because IRL typically seeks a reward function that makes the demonstrator appear near-optimal, rather than inferring the underlying intentions of the demonstrator that may have been poorly executed in practice. In this paper, we introduce a novel reward-learning-from-observation algorithm, Trajectory-ranked Reward EXtrapolation (T-REX), that extrapolates beyond a set of (ap- proximately) ranked demonstrations in order to infer high-quality reward functions from a set of potentially poor demonstrations. When combined with deep reinforcement learning, T-REX outperforms state-of-the-art imitation learning and IRL methods on multiple Atari and MuJoCo bench- mark tasks and achieves performance that is often more than twice the performance of the best demonstration. We also demonstrate that T-REX is robust to ranking noise and can accurately extrapolate intention by simply watching a learner noisily improve at a task over time.”
In the abstract you can read: “For sophisticated reinforcement learning (RL) systems to interact usefully with real-world environments, we need to communicate complex goals to these systems. In this work, we explore goals defined in terms of (non-expert) human preferences between pairs of trajectory segments. We show that this approach can effectively solve complex RL tasks without access to the reward function, including Atari games and simulated robot locomotion, while providing feedback on less than one percent of our agent’s interactions with the environment. This reduces the cost of human oversight far enough that it can be practically applied to state-of-the-art RL systems. To demonstrate the flexibility of our approach, we show that we can successfully train complex novel behaviors with about an hour of human time. These behaviors and environments are considerably more complex than any that have been previously learned from human feedback.
In the abstract you can read: “Conceptual abstraction and analogy-making are key abilities underlying humans’ abilities to learn, reason, and robustly adapt their knowledge to new domains. Despite of a long history of research on constructing AI systems with these abilities, no current AI system is anywhere close to a capability of forming humanlike abstractions or analogies. This paper reviews the advantages and limitations of several approaches toward this goal, including symbolic methods, deep learning, and probabilistic program induction. The paper concludes with several proposals for designing challenge tasks and evaluation measures in order to make quantifiable and generalizable progress
In the abstract you can read: “Since its beginning in the 1950s, the field of artificial intelligence has cycled several times between periods of optimistic predictions and massive investment (“AI spring”) and periods of disappointment, loss of confidence, and reduced funding (“AI winter”). Even with today’s seemingly fast pace of AI breakthroughs, the development of long-promised technologies such as self-driving cars, housekeeping robots, and conversational companions has turned out to be much harder than many people expected. One reason for these repeating cycles is our limited understanding of the nature and complexity of intelligence itself. In this paper I describe four fallacies in common assumptions made by AI researchers, which can lead to overconfident predictions about the field. I conclude by discussing the open questions spurred by these fallacies, including the age-old challenge of imbuing machines with humanlike common sense.”
[] Stuart Russell, (2019), Human Compatible: AI and the Problem of Control, Penguin books, Allen Lane; 1. Edition (8. Oktober 2019)
In the preface you can read: “This book is about the past , present , and future of our attempt to understand and create intelligence . This matters , not because AI is rapidly becoming a pervasive aspect of the present but because it is the dominant technology of the future . The world’s great powers are waking up to this fact , and the world’s largest corporations have known it for some time . We cannot predict exactly how the technology will develop or on what timeline . Nevertheless , we must plan for the possibility that machines will far exceed the human capacity for decision making in the real world . What then ? Everything civilization has to offer is the product of our intelligence ; gaining access to considerably greater intelligence would be the biggest event in human history . The purpose of the book is to explain why it might be the last event in human history and how to make sure that it is not .”
[] David Adkins, Bilal Alsallakh, Adeel Cheema, Narine Kokhlikyan, Emily McReynolds, Pushkar Mishra, Chavez Procope, Jeremy Sawruk, Erin Wang, Polina Zvyagina, (2022), Method Cards for Prescriptive Machine-Learning Transparency, 2022 IEEE/ACM 1st International Conference on AI Engineering – Software Engineering for AI (CAIN), CAIN’22, May 16–24, 2022, Pittsburgh, PA, USA, pp. 90 – 100, Association for Computing Machinery, ACM ISBN 978-1-4503-9275-4/22/05, New York, NY, USA, https://doi.org/10.1145/3522664.3528600
In the abstract you can read: “Specialized documentation techniques have been developed to communicate key facts about machine-learning (ML) systems and the datasets and models they rely on. Techniques such as Datasheets, AI FactSheets, and Model Cards have taken a mainly descriptive approach, providing various details about the system components. While the above information is essential for product developers and external experts to assess whether the ML system meets their requirements, other stakeholders might find it less actionable. In particular, ML engineers need guidance on how to mitigate po- tential shortcomings in order to fix bugs or improve the system’s performance. We propose a documentation artifact that aims to provide such guidance in a prescriptive way. Our proposal, called Method Cards, aims to increase the transparency and reproducibil- ity of ML systems by allowing stakeholders to reproduce the models, understand the rationale behind their designs, and introduce adap- tations in an informed way. We showcase our proposal with an example in small object detection, and demonstrate how Method Cards can communicate key considerations that help increase the transparency and reproducibility of the detection model. We fur- ther highlight avenues for improving the user experience of ML engineers based on Method Cards.”
[] John H. Miller, (2022), Ex Machina: Coevolving Machines and the Origins of the Social Universe, The SFI Press Scholars Series, 410 pages Paperback ISBN: 978-1947864429 , DOI: 10.37911/9781947864429
In the announcement of the book you can read: “If we could rewind the tape of the Earth’s deep history back to the beginning and start the world anew—would social behavior arise yet again? While the study of origins is foundational to many scientific fields, such as physics and biology, it has rarely been pursued in the social sciences. Yet knowledge of something’s origins often gives us new insights into the present. In Ex Machina, John H. Miller introduces a methodology for exploring systems of adaptive, interacting, choice-making agents, and uses this approach to identify conditions sufficient for the emergence of social behavior. Miller combines ideas from biology, computation, game theory, and the social sciences to evolve a set of interacting automata from asocial to social behavior. Readers will learn how systems of simple adaptive agents—seemingly locked into an asocial morass—can be rapidly transformed into a bountiful social world driven only by a series of small evolutionary changes. Such unexpected revolutions by evolution may provide an important clue to the emergence of social life.”
In the abstract you can read: “Analyzing the spatial and temporal properties of information flow with a multi-century perspective could illuminate the sustainability of human resource-use strategies. This paper uses historical and archaeological datasets to assess how spatial, temporal, cognitive, and cultural limitations impact the generation and flow of information about ecosystems within past societies, and thus lead to tradeoffs in sustainable practices. While it is well understood that conflicting priorities can inhibit successful outcomes, case studies from Eastern Polynesia, the North Atlantic, and the American Southwest suggest that imperfect information can also be a major impediment to sustainability. We formally develop a conceptual model of Environmental Information Flow and Perception (EnIFPe) to examine the scale of information flow to a society and the quality of the information needed to promote sustainable coupled natural-human systems. In our case studies, we assess key aspects of information flow by focusing on food web relationships and nutrient flows in socio-ecological systems, as well as the life cycles, population dynamics, and seasonal rhythms of organisms, the patterns and timing of species’ migration, and the trajectories of human-induced environmental change. We argue that the spatial and temporal dimensions of human environments shape society’s ability to wield information, while acknowledging that varied cultural factors also focus a society’s ability to act on such information. Our analyses demonstrate the analytical importance of completed experiments from the past, and their utility for contemporary debates concerning managing imperfect information and addressing conflicting priorities in modern environmental management and resource use.”